
使用 OpenLLM 和 Vultr Cloud GPU 构建 AI 驱动的应用程序
OpenLLM 是一个开源平台,可让您创建支持 AI 的生产应用程序,例如个性化聊天机器人、推荐系统等。它允许您通过发送 API 提示和参数来生成响应,以操纵响应。 OpenLLM 的库包含所有主要模型,如 Mistral、Falcon 和 Llama。
在本文中,我们将演示如何在 Vultr GPU 服务器上使用 OpenLLM 部署 Falcon 7B 模型来生成 API 响应,这些响应可用于创建支持 AI 的应用程序。您将学习如何安装必需的依赖项以及如何创建具有持久性的 OpenLLM 服务。此外,我们将介绍如何将 Nginx 配置为反向代理以实现高效的负载均衡,并使用安全套接字层 (SSL) 证书保护您的应用程序以启用 HTTPS。
在 Vultr 上部署服务器
要高效地部署人工智能 (AI) 或机器学习 (ML) 支持的应用程序,使用云 GPU 是最有效的方法之一。云 GPU 提供对最新技术的访问,使您能够持续构建、部署和全局服务大规模应用程序。
-
注册并登录 Vultr 客户门户。
-
导航到产品页面。
-
从侧边菜单中,选择计算。
-
点击中心的部署服务器按钮。
-
选择云 GPU 作为服务器类型。
-
选择A40 作为 GPU 类型。
-
在“服务器位置”部分,选择您选择的区域。
-
在“操作系统”部分,选择Vultr GPU Stack 作为操作系统。
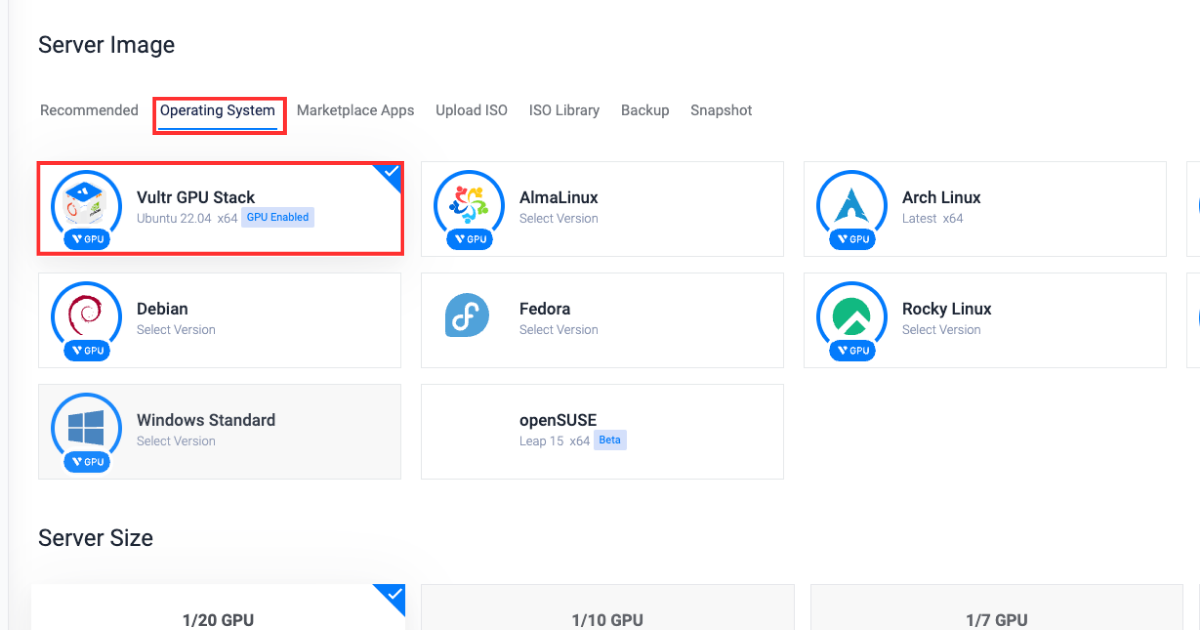
Vultr GPU Stack 旨在通过提供一套全面的预装软件(包括 NVIDIA CUDA Toolkit、NVIDIA cuDNN、Tensorflow、PyTorch 等)来简化构建人工智能 (AI) 和机器学习 (ML) 项目的过程。
-
在“服务器大小”部分,选择48 GB 选项。
-
在“附加功能”部分,根据需要选择任何其他功能。
-
点击右下角的立即部署按钮。
安装必需的软件包
根据前面的说明设置 Vultr 服务器后,本节将指导您安装运行 OpenLLM 所需的依赖 Python 包并验证安装。
-
安装必需的软件包。
bashpip3 install openllm scipy xformers einops每个软件包代表的含义如下:
xformers:为构建基于 Transformer 的模型提供多种构件。einops:重塑和减少多维数组的维度。scipy:解决复杂的数学问题,并具有操作和可视化数据的能力。openllm:提供运行 OpenLLM 服务所需的依赖项。
-
验证安装。
bashopenllm -h如果安装成功,系统将找到并执行
openllm,显示其帮助信息。这表明openllm已正确安装并被系统识别。如果openllm未正确安装,该命令很可能会返回错误。
创建 OpenLLM 服务
在本节中,您将学习如何创建一个 OpenLLM 服务,该服务将在系统启动时自动启动服务,并运行 Falcon 7B 模型进行推理。
-
获取
openllm路径。bashwhich openllm -
复制并粘贴路径到剪贴板。您将在第 4 步中使用它。
-
创建 OpenLLM 服务文件。
bashnano /etc/systemd/system/openllm.service -
将以下内容粘贴到服务文件中。请确保将
User和Group值替换为您实际的值。还将WorkingDirectory替换为 OpenLLM 路径(不包括您之前复制的openllm),并将Execstart替换为包含可执行二进制文件的实际 OpenLLM 路径。bash[Unit] Description= Daemon for OpenLLM Demo Application After=network.target [Service] User=example_user Group=example_user WorkingDirectory=/home/example_user/.local/bin/ ExecStart=/home/example_user/.local/bin/openllm start tiiuae/falcon-7b --backend pt [Install] WantedBy=multi-user.target -
启动服务。
bashsystemctl start openllm -
验证服务状态。
bashsystemctl status openllm输出将如下所示
● openllm.service - Daemon for OpenLLM Demo Application Loaded: loaded (/etc/systemd/system/openllm.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2023-11-29 20:51:25 UTC; 12min ago Main PID: 3160 (openllm) Tasks: 257 (limit: 72213) Memory: 21.9G CGroup: /system.slice/openllm.service ├─3160 /usr/bin/python3 /usr/local/bin/openllm start tiiuae/falcon-7b --backend pt -
启用服务,以便在系统每次启动时自动启动。
bashsystemctl enable openllm
将 Nginx 配置为反向代理服务器
Nginx 在您的 Web 服务器和客户端之间充当反向代理。它根据您的请求配置设置来路由传入的请求。
在本节中,您将学习如何为 OpenLLM 应用程序配置反向代理,以使用 Nginx 实现高效的请求处理和负载均衡。您还将学习如何配置 OpenLLM 本身以实现反向代理功能。
-
登录 Vultr 客户门户。
-
导航到产品页面。
-
从侧边菜单中,展开网络下拉菜单,然后选择DNS。
-
点击中心的添加域名按钮。
-
通过选择您的服务器 IP 地址,按照设置过程添加您的域名。
-
在您的域名注册商处将以下主机名设置为您域名的主和辅助名称服务器。
- ns1.vultr.com
- ns2.vultr.com
-
安装 Nginx。
bashsudo apt install nginx -
在
sites-available目录中创建一个名为openllm.conf的文件。bashsudo nano /etc/nginx/sites-available/openllm.conf -
将以下内容粘贴到
openllm.conf文件中。请确保将example.com替换为您实际的域名。bashserver { listen 80; listen [::]:80; server_name example.com www.example.com; location / { proxy_pass http://127.0.0.1:3000/; } }以上虚拟主机配置中使用了以下指令:
server:定义我们域名的设置块。listen:指示服务器在端口80上监听传入的请求。server_name:指定此服务器块将响应的域名。location:定义服务器应如何处理传入的请求。proxy_pass:指示服务器将请求转发到另一个位置,在本例中是http://127.0.0.1:3000/。
-
保存文件,然后退出编辑器。
-
通过将
openllm.conf文件链接到sites-enabled目录来激活虚拟主机配置。bashsudo ln -s /etc/nginx/sites-available/openllm.conf /etc/nginx/sites-enabled/ -
测试配置以找出错误。
bashsudo nginx -t如果配置没有错误,您的输出应如下所示:
bashnginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful -
重启 Nginx 服务器。
bashsudo systemctl reload nginx -
允许端口
80上的传入连接。bashsudo ufw allow 80/tcp
使用 Certbot 安装 SSL 证书
Certbot 允许您从“Let's Encrypt”(一个免费证书颁发机构)获取 SSL 证书。这些 SSL 证书充当加密密钥,可在用户和 Web 服务器之间实现安全通信。
在本节中,您将学习如何为您的域名请求“Let's Encrypt”的免费 SSL 证书,并为您的应用程序实现 HTTPS。您还将学习如何设置证书在 90 天内到期前自动续订。
-
允许端口
443上的传入连接以实现 HTTPS。bashsudo ufw allow 443/tcp -
使用
snap包管理器安装certbot包。bashsudo snap install --classic certbot -
为您的域名请求新的 SSL 证书。请确保将
example.com替换为您实际的域名。bashsudo certbot --nginx -d example.com -d www.example.com -
您可以在以下链接中访问 OpenLLM API 文档:
urlhttps://example.com
使用 OpenLLM 生成 API 响应
在配置了 Nginx 和 SSL 之后,本节将指导您向负责从给定提示生成响应的 OpenLLM 端点发送 API POST 请求。
向 API 端点发送 curl 请求。
curl -X POST -H "Content-Type: application/json" -d '{
"prompt": "What is the meaning of life?",
"stop": ["\n"],
"llm_config": {
"max_new_tokens": 128,
"min_length": 0,
"early_stopping": false,
"num_beams": 1,
"num_beam_groups": 1,
"use_cache": true,
"temperature": 0.75,
"top_k": 15,
"top_p": 0.9,
"typical_p": 1,
"epsilon_cutoff": 0,
"eta_cutoff": 0,
"diversity_penalty": 0,
"repetition_penalty": 1,
"encoder_repetition_penalty": 1,
"length_penalty": 1,
"no_repeat_ngram_size": 0,
"renormalize_logits": false,
"remove_invalid_values": false,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"encoder_no_repeat_ngram_size": 0,
"logprobs": 0,
"prompt_logprobs": 0,
"n": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"use_beam_search": false,
"ignore_eos": false,
"skip_special_tokens": true
},
"adapter_name": null
}' https://example.com/v1/generate
您可以通过更改各种参数的值来调整响应的强度。以下是每个参数作用的解释:
top_p:负责选择输出的最佳概率标记,使输出更具针对性和相关性。epsilon_cutoff:负责忽略概率低于 epsilon 值的标记,从而忽略低概率选项。diversity_penalty:负责影响输出的多样性。较高的参数值将产生更多样化且重复性较低的响应。repetition_penalty:负责对生成输出中连续重复的标记施加惩罚。length_penalty:负责控制响应的长度;较高的参数值会生成更长的响应,反之亦然。no_repeat_ngram_size:负责惩罚在响应中已出现过的 n-gram(n 个标记的序列)的标记。remove_invalid_values:负责从生成响应中自动删除具有无效值的标记。num_return_sequences:负责控制模型在响应中应生成的不同序列的数量。frequency_penalty:负责操纵模型在生成响应时选择某些标记的频率。use_beam_search:如果参数值设置为 true,则负责使用束搜索查找用于响应生成的相关续写。ignore_eos:如果参数值设置为 true,则负责在生成响应时忽略“句子结束”标记。n:代表每个生成响应中的标记数量。
这是 curl 请求的示例输出:
{
"prompt": "What is the meaning of life?",
"finished": true,
"outputs": [
{
"index": 0,
"text": " What is the meaning of the universe? How does the universe work?",
"token_ids": [
1634, 304, 248, 4113, 275, 248, 10314, 42, 1265, 960, 248, 10314, 633,
42, 193, 1265, 960, 248, 10314, 633, 42, 193
],
"cumulative_logprob": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"prompt_token_ids": [1562, 304, 248, 4113, 275, 1063, 42],
"prompt_logprobs": null,
"request_id": "openllm-e1b145f3e9614624975f76e7fae6050c"
}
总结
在本文中,您学习了如何使用 OpenLLM 和 Vultr GPU Stack 为 AI 驱动的应用程序构建 API 响应。本教程指导您完成了创建 OpenLLM 服务的步骤,该服务初始化了生成响应所需的模型和 API 端点。您还学习了如何将 Nginx 设置为 OpenLLM 服务的反向代理服务器,并使用 SSL 证书对其进行保护。
这是一篇由 Vultr 赞助的文章。Vultr 是全球最大的私营云计算平台。Vultr 是开发者的首选,已为 185 个国家/地区的 150 万多客户提供了灵活、可扩展、全球化的云计算、云 GPU、裸金属和云存储解决方案。了解更多关于 Vultr 的信息。