
从编码器到解码器的像素数据
在上一篇文章中,我们重点讨论了人眼如何看到图像以及设备如何显示图像。现在,是时候放大并探索图像的微小构件——像素及其背后的字节了。
什么是图像像素?
要显示一幅图像,设备需要从数据源获取图像不同部分的颜色信息。对于设备来说,大多数图像只是网格,网格中的每个单元格都是一个像素。像素是一个短暂的值;它没有大小或形状。如何表示这些像素,取决于硬件和软件。
存储像素数据的方式有无数种,因此设备需要理解图像格式,即数据的组织方式。在 Web 上,有几种常见的格式:JPEG、AVIF、WebP、JPEG XL、PNG 等等。像素有几个重要的属性:
- 它们排列成网格以形成图像,顺序很重要。
- 每个像素都包含颜色和亮度信息。这些值是离散的,并受图像格式定义的比特数限制。
注意: AVIF 可以使用 8、10 或 12 比特来存储像素数据。一种较新的 JPEG 格式 JPEG XL,每个颜色通道支持高达 32 比特。最常见的设置是每通道 8 比特,取值范围从 0 到 255。这为每个颜色分量只提供了 256 种可能的“色度”——总共大约有 256 × 256 × 256 ≈ 1600 万种可能的颜色。
了解图像像素和设备像素之间的区别很重要。图像像素是图像数据的一部分,而设备像素是依赖于显示器的物理像素。设备像素的工作方式各不相同:例如,在 OLED 屏幕中,每个像素是一个微小的发光二极管;在 LCD 中,它是由背光控制的晶体;在电子墨水屏中,它是由移动形成图像的带电粒子组成的。
显卡中的图像
为了让显示器显示图像,显卡需要将该图像作为信号发送到显示器。一个简化的解释是,显卡将图像像素数据存储为一个数字数组。让我们看看如何在 JavaScript 中操作像素数据:
<div class="symbols-holder"></div>
.symbols-holder {
font-family: monospace;
white-space: pre;
font-size: 5px;
line-height: 3px;
}
const imageToSymbols = (src, showPixelsSomehow) => {
const img = new Image(); // create an image element
img.onload = () => {
const width = 128;
const height = 128;
const canvas = new OffscreenCanvas(width, height);
const ctx = canvas.getContext("2d");
ctx?.drawImage(img, 0, 0);
const resp = ctx.getImageData(0, 0, width, height); // read image data
let str = "";
// convert image data to string
for (let i = 0; i < resp.data.length; i += 4) {
// use opacity channel
str += resp.data[i + 3] > 255 / 2 ? "*" : ".";
if (i % (4 * width) === 0) {
str += "\n";
}
}
showPixelsSomehow(str);
};
img.src = src;
};
imageToSymbols("squirrel.png", show);
提取的 ImageData 是一个连续的无符号 1 字节整数的类型化数组。在这个例子中,图像不包含任何颜色。相反,每个图像像素有四个分量,所有有趣的信息都存储在第四个分量——alpha 通道中。通过读取每四个元素,我们可以通过 alpha 通道扫描整个图像。
注意: alpha 通道存储有关图像透明度的信息。值为 255 表示像素完全不透明,而 0 表示完全透明。
图像规范
举个例子,让我们看一张非常小的 100×133 像素的图像:

如果没有 alpha 通道——意味着每个像素只有三个分量——并且我们使用 8 位色,那么图像的原始大小应该在 40 KB 左右。但实际文件不到 3 KB。很快就会明白为什么。对于更大的图像,这种差异会变得更加显著。
现在想象一下,不是单张图像,而是需要渲染一段 60 秒的短视频。以每秒 24 帧计算,总共有 1,440 帧。每帧 38 KB,总大小将在 55 MB 左右。显然,需要高效地打包像素。为了处理这个问题,已经开发了许多图像和视频格式:BMP、GIF、JPEG、PNG、JPEG2000、多个版本的 MPEG、H.264、VP8、VP9 和 AV1。
因此,数据首先被编码,然后再被解码——处理这个过程的东西被称为编解码器(coder, decoder)。编码可以在 CPU 或 GPU 上进行。通常,图像数据存放在 RAM 中,CPU 对其进行解码,然后结果被发送到 GPU,以便在屏幕上显示。但当处理量变大时——比如视频播放——上传压缩的图像数据会更高效。在这种情况下,GPU 会自己进行解码。
视频由两种类型的帧组成:内帧(intraframe)和间帧(interframe)。内帧基本上是被压缩的完整图像,而间帧存储的是图像部分从一帧到下一帧如何移动的信息。
注意: 更准确地说,间帧包含运动矢量。
内帧压缩的工作原理与图像压缩完全相同。像 AVIF、HEIF 和 WebP 这样的格式实际上是基于相关视频编解码器中使用的内帧压缩技术。总的来说,编解码器的发展速度比图像格式快,因此图像格式往往成为视频编解码器开发的副产品。
例如,在现代图像格式还未被浏览器广泛支持的过去(现在情况已不同),人们会使用单帧视频来代替图像。
图像编码器的工作原理
编码器生成的比特序列称为比特流。要传输或存储这些数据,需要将其分割成块。这些块根据格式的不同有不同的名称。例如,在 AV1 视频和 AVIF 图像中,它们被称为 OBU(Open Bitstream Units,开放比特流单元)。每个单元都有自己的结构,以便解码器知道如何处理它。
但一张图像通常不仅仅是一系列比特流单元。如前所述,它还可以包含 ICC 配置文件和其他元数据——比如图像尺寸、色彩空间、相机设置、日期、时间和地点。所有这些都需要被打包到一个容器中。
容器有自己的规范,不同的媒体格式可以重复使用同一个容器。例如:
- AVIF 是一个位于 HEIF 容器中的 AV1 字节流。
- WebP 是一个位于 RIFF 容器中的 VP8 字节流(或无损 WebP)。
有时,一种图像格式会定义自己的容器。PNG、JPEG 和 JPEG XL 将布局作为文件格式规范的一部分。
图像解码器的工作原理
解码器通过读取文件开头来确定格式,文件开头通常包含一个幻数——几个用于标识格式的字节。对于 AVIF,这个幻数是 ftypavif。
然后它会遵循容器布局来找到相关数据。通常,元数据在前,然后是实际的字节流。让我们用一些松鼠图片来看看这是如何工作的 😀

该图像在文件开头包含大量元数据:
width: 1536 height: 1536 bands: 3 format: uchar coding: none interpretation: srgb xoffset: 0 yoffset: 0 xres: 2.83465 yres: 2.83465 filename: ./squirrel.jpg vips-loader: jpegload jpeg-multiscan: 1 interlaced: 1 jpeg-chroma-subsample: 4:2:0
如果大部分内容目前还看不懂,没关系——其中一些条目稍后会解释。如你所见,宽度和高度存储在容器的开头。这对浏览器特别有用,可以快速在页面上为图像分配空间。
注意: 不要让浏览器自己计算图像的高度和宽度——这会导致恼人的布局偏移。相反,应该在 <img> 元素上设置 width 和 height 属性。
深入了解编码器
那么编码器如何能将 38 KB 的图像数据压缩到仅 3 KB 呢?编码器使用了一系列技术和算法,利用了我们感知图像的方式以及图像的结构。让我们逐一了解它们。
有损和无损压缩方法
压缩图像有两种方法:
- 有损: 编码后的图像会改变或移除一些信息,不再与原始图像完全相同。
- 无损: 图像可以被完全重建。
有损和无损压缩方法可以结合使用,有时可以用更少的字节提供更好的结果。例如,alpha 通道(控制不透明度)可以无损压缩,而颜色通道使用有损压缩以提高效率。
下表总结了几种流行的图像格式:
| 格式 | 压缩类型 | 注意 |
|---|---|---|
| PNG | 无损 | 始终无损 |
| JPEG | 有损 | 始终有损 |
| WebP | 混合 | 可以是有损的 VP8 帧,或使用不同算法的无损帧 |
| AVIF | 有损或无损 | |
| JPEG XL | 有损或无损 |
色度子采样
人类对亮度的敏感度远高于对颜色的敏感度。YCbCr 色彩空间利用了这一事实,将亮度(luminance)与颜色信息分开,从而实现更高效的压缩。
编码器不是存储每个像素的完整颜色细节,而是跳过部分颜色数据。然后解码器根据附近像素的颜色重建它。这种技术被称为色度二次采样。
色度二次采样使用三个数字来描述,对应一个 4×2 的像素网格:
- 第一个数字总是 4,代表区域的宽度。
- 第二个数字显示第一行存储了多少色度样本(Cb 和 Cr)。
- 第三个数字显示第二行存储了多少色度样本。
AVIF 支持以下色度二次采样格式:
- 4:4:4 – 无二次采样;所有颜色信息都被保留。
- 4:2:2 – 一半的颜色信息被丢弃。
- 4:2:0 – 仅保留原始颜色数据的四分之一。
这是一个有损变换的例子。一旦应用,原始图像就无法完全恢复,但对观看者来说看起来仍然相当不错,同时节省了存储空间和带宽。
利用空间局部性
让我们看一个代码示例来演示下一个技术。这里有两个画布:一个带有随机像素,另一个带有纯色。
const width = 100;
const height = 100;
let ctx = canvas1.getContext("2d");
for (let i = 0; i < width; i++) {
for (let j = 0; j < height; j++) {
ctx.fillStyle = `rgb(${Math.random() * 255}, ${Math.random() * 255}, ${
Math.random() * 255
})`;
ctx.fillRect(i, j, 1, 1);
}
}
ctx = canvas2.getContext("2d");
ctx.fillStyle = "rgba(6, 142, 110, 0.81)";
ctx.fillRect(0, 0, width, height);
尝试分别保存这两张图片:右键点击每张图片并选择“图片另存为”。即使使用效率不高的浏览器编解码器,第一张图片的大小也约为 35 KB,而第二张图片仅为 500 字节。大小相差 70 倍!
原因是第一张图片中的像素之间没有任何关系。在真实图像中,相邻像素通常以某种方式相关。它们可能共享相同的颜色、形成渐变或遵循某种模式。这个属性被称为空间局部性。

一张图像包含的信息越少,它就越能被更好地压缩。编解码器充分利用了这个属性,将图像分成区域并分别压缩每个区域。
例如,JPEG 总是将图像分割成 8×8 的块。更现代的图像格式允许灵活的块大小。例如,AVIF 使用从 4×4 到 128×128 的块。编解码器通常坚持使用 2 的幂次方作为块大小,以保持计算简单高效。
对于一张有纯蓝色天空的图像,将该区域划分为更大的块更有效率,这减少了存储不必要细节的需求。同样的规则适用于任何纯色背景。但编码器如何决定在何处以及如何分割图像呢?有几种技术可以实现这一点,我们接下来可以探讨。
AVIF 使用递归方法将图像分割成块。它首先将图像分割成更大的块,称为超级块。然后,它分析每个块的内容,并决定是进一步分割还是保持原样。为了管理这种分区,AVIF 使用一种四叉树数据结构。四叉树也常用于地图应用中,用于存储位置并高效地查找附近的物体。
你可以通过递归地将图像分割成四个方块来自己构建一个四叉树。对于每个方块,计算平均颜色和与平均值的偏差。如果偏差太大,就再次分割该方块。
function buildQuadtree(params) {
const { x, y, w, h, forceSplitSize, minSize, threshold, data, totalWidth } =
params;
// always split big regions
const forced = w > forceSplitSize && h > forceSplitSize;
const std = regionStd(x, y, w, h, data, totalWidth);
// if the region is too small or color varies little, stop
if (w <= minSize || h <= minSize || (!forced && std < threshold)) return;
ctx.strokeRect(x, y, w, h);
const midW = (w / 2) | 0;
const midH = (h / 2) | 0;
if (midW === 0 || midH === 0) return;
const nextParams = { ...params, w: midW, h: midH };
// left top
buildQuadtree({ ...nextParams });
// right top
buildQuadtree({ ...nextParams, x: x + midW, y });
// left bottom
buildQuadtree({ ...nextParams, x, y: y + midH });
// right bottom
buildQuadtree({
...nextParams,
x: x + midW,
y: y + midH,
});
}
function showSplit(imgData, totalWidth) {
const params = {
threshold: 28,
minSize: 8,
forceSplitSize: 128,
totalWidth,
};
buildQuadtree({
x: 0,
y: 0,
w: totalWidth,
h: totalWidth,
data: imgData.data,
...params,
});
}
预测模式
一个块包含的数据越少,它就能被更好地压缩。通过点击下面的画布上的不同单元格来尝试一个 8×8 像素的块。点击几次后,标记为绿色的部分图案将被重现。
与其存储网格中的每个像素,不如只存储实际图像与最匹配模式之间的差异,这样可以节省空间。
现代图像编解码器使用同样的想法。它们为每个块预测一个基本结构,然后只压缩实际块内容与预测之间的差异,称为残差。
大多数图像都有一些潜在的结构,编解码器通过分析梯度或重复纹理等模式来利用这一点,以做出更好的预测。

块内的像素通常形成一个与其相邻值相关的模式。因此,编解码器不使用静态模式,而是使用块的顶行和左列作为参考来进行预测。看图中的左边例子:方块内的像素与一些周围的像素非常相似。
不同的编解码器使用各种预测模式来找到表示这种结构并最小化误差的最佳方式。例如:
- 该块可以被预测为其相邻像素的平均值。
- 它可以沿特定方向重复像素(如图所示)。
- 它可能会组合多个相邻像素以创建更准确的预测。
- 更高级的预测器会考虑块内每个像素的坐标来优化结果。
- 更高级的模式更进一步,通过递归地预测前几行和前几列的像素。编码器不只依赖于参考像素,而是使用先前预测的像素生成补丁。
通过改进这些预测,编解码器可以显著减少需要存储或传输的数据量。例如,AVIF 的一种预测模式是基于左邻参考像素、右上参考像素以及块内像素的坐标。
预测不仅限于空间结构——颜色通道也可以相互关联。这个想法在 AVIF 和 JPEG XL 中都有使用。相关的预测模式,色度来自亮度,是根据相应的 Y(亮度)通道信息来预测颜色通道(UV)。一些编解码器,不是预测像素,而是可以存储一条指令来复制另一个块的内容。这对于截图或具有重复图案的图像特别有用,因为它减少了冗余。
不同编解码器的预测模式数量各不相同。AVIF 有很多(71个),WebP 较少(10个),而 JPEG 完全不使用预测。
块变换
编解码器进行预测,然后找出与该预测的像素差异。接下来,编解码器需要高效地存储这些差异,这时候就需要丢弃一些数据,即应用有损变换。
你可以用同样的模式类比来思考。现在有一组固定的模式,目标是找出组合它们的最佳方式,以得到接近原始块的东西。这就像通过堆叠多个具有不同不透明度的图层来构建图像——每个图层都对最终结果有贡献,诀窍是为每个图层猜对正确的不透明度。实现这一点的数学方法叫做离散余弦变换(DCT)。
为什么这有助于减小文件大小?人类对高频分量(如微小的点或精细的纹理)不太敏感。变换将这些高频和低频部分分离开来,使得决定哪些细节可以安全丢弃变得更容易。
一种著名的可视化方式是通过 DCT 基函数,它显示了不同频率分量如何对图像做出贡献。
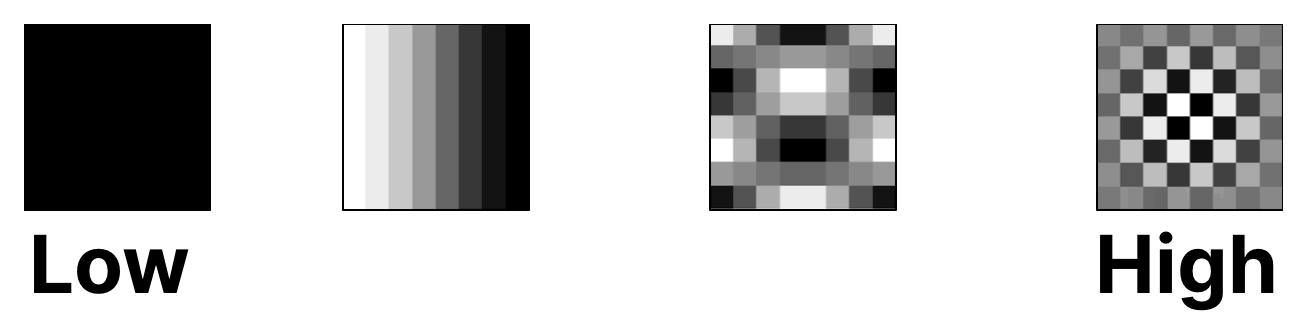
注意: 虽然这是一个有用的图示,但请记住,现代编解码器是对残差而不是原始图像应用变换。
让我们通过一个例子来看看这是如何工作的。想象一个 8×8 的块,中间有一条水平的 2 像素粗的线:
.out {
font-family: monospace;
white-space: pre;
}
const block = [
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1], // <- line
[1, 1, 1, 1, 1, 1, 1, 1], // <- line
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
];
// special weight function
const alpha = (u, size) =>
u === 0 ? 1 / Math.sqrt(size) : Math.sqrt(2 / size);
// A very naive and innefficient implementation of 2D DCT
const dct2D = (block) => {
const size = block.length;
// create block of the same size
const result = Array.from({ length: size }, () => Array(size).fill(0));
// apply DCT formula
for (let u = 0; u < size; u++) {
for (let v = 0; v < size; v++) {
let sum = 0;
for (let x = 0; x < size; x++) {
for (let y = 0; y < size; y++) {
sum +=
block[x][y] *
Math.cos(((2 * x + 1) * u * Math.PI) / (2 * size)) *
Math.cos(((2 * y + 1) * v * Math.PI) / (2 * size));
}
}
result[u][v] = alpha(u, size) * alpha(v, size) * sum;
}
}
return result;
};
当然,实际的实现是高效且经过优化的:
- 编解码器不是一次性对整个块应用 DCT,而是首先对行使用两个一维 DCT,然后再对列使用。
- 一些编解码器支持替代变换。例如,AVIF 可以使用离散正弦变换代替 DCT。
- 编解码器使用快速算法,如基于蝶形图的快速 DCT。
- 变换步骤使用 SIMD 指令进行矢量运算优化,这让 CPU 可以用一个命令对多个值应用相同的操作。
- DCT 也可以直接在 GPU 上执行。AV1 编解码器(AVIF 的基础)支持这一点。
在更高级的编解码器中,变换可以应用于块的一部分而不是整个块。例如,AVIF 允许一个块被细分(最多两次)成更小的块,并对每个子块分别应用变换。
在这个阶段,由于浮点计算中的舍入,会引入一个小的有损误差。但仅这一步并不会显著减小文件大小。
量化
为了准备图像进行压缩,编解码器将浮点系数转换为整数,并用一个特定的数字去除它们。目标是在除法后得到尽可能多的零——数据越少意味着压缩效果越好。这些数字被称为量化参数。
在 JPEG 中使用的一组流行的量化值如下所示:
这些参数对于亮度和颜色通道是不同的。
量化参数存储在图像容器中,对于 JPEG,质量取决于我们如何缩放这些参数。系数越大,应用后得到的零就越多。
在更高级的编解码器中,这个过程要复杂得多。使用专门的算法来正确地对量化结果进行舍入。此外,可以对不同的块组应用不同的量化参数,从而使图像不同部分的质量有所不同。
附加内容:交错
由于不同的系数代表不同层次的细节,因此几乎可以免费实现交错(也称为渐进式渲染)。为此,系数被重新排序,以便具有粗略(基本)细节的系数被首先存储(和加载)。
结果是,图像以多个细节层次构建,称为扫描。第一次扫描显示图像的粗略、通常是模糊的版本。随后的每次扫描都会逐步添加更多细节。
对于大多数图像格式,这种重新排序不会增加文件大小,所以这是一个有用的小技巧。但要小心交错的 PNG——它们使用一种不同的方法,确实会增加文件大小。
熵编码
现在我们接近最后一步了,是时候解释为什么纯色图像比随机噪声小这么多了。原因是熵编码。
编解码器获得量化系数后,下一步是尽可能地缩小二进制大小。块的系数按之字形顺序扫描,得到的序列使用熵编码家族中的算法进行编码。这个想法很简单:为出现频率更高的值使用更少的比特。
让我们自己尝试编码一个基本版本。假设我们有这样一串数字:
124 124 124 124 10 123 123 1 1 2
第一步是计算每个数字在序列中出现的频率。
const vals = "124 124 124 124 10 123 123 1 1 1 2"
.split(" ")
.map((e) => parseInt(e, 10));
// count how many times each value appears
const groups = Object.groupBy(vals, (e) => e);
// sort the result, most frequent first
const freqs = Object.entries(groups)
.map(([key, value]) => [key, value.length])
.sort((a, b) => b[1] - a[1]);
现在我们可以为最频繁的值分配最短的二进制代码,像这样:
124 - 0 1 - 10 123 - 110 2 - 1110 10 - 1111
我们可以只用 24 个比特而不是 88 个比特来编码这个字符串:000011111101101010101110 🎉。这就是 JPEG 实现压缩的方式。使用的算法被称为霍夫曼编码。
一些编解码器使用更高级的算法,如算术编码或非对称数字系统。算术编码允许压缩更接近理论极限,与霍夫曼编码相比,实现了更高的压缩率。
注意: 这个极限由数据的香农熵定义。它代表了编码该数据所需的最少比特数。
后处理
有损压缩会引入各种失真,因为它移除了高频分量。这可能导致几种可见的效果,例如:
- 块效应 – 可见的方形图案,尤其是在平坦区域
- 边缘模糊
- 颜色失真 – 不准确或偏移的颜色
- 振铃效应 – 边缘周围的光晕或回声状图案
- 蚊式噪声 – 边缘周围的小闪烁点或嗡嗡声

为了减少这些失真,一些编码器会添加后处理滤波器。这些滤波器由解码器在重建图像像素时应用。滤波器的设置存储在字节流中,因此解码器可以在解码期间读取并应用它们。
你可能还记得对图像应用高斯模糊来减少噪声的老技巧。这与此类似,但现代编解码器使用更高级的算法。
- 去块效应滤波器 – 例如,JPEG XL 中使用的 Gabor 滤波器
- 维纳滤波器 – 用于 AV1 中以减少噪声
- CDEF(约束方向增强滤波器)– 有助于减少振铃失真
通常,如果使用多个滤波器,它们会形成一个具有精确应用顺序的流水线。例如,CDEF 在去块效应滤波器之后应用。
总结
在本文中,我们探讨了图像编码的工作原理,它与人类感知的联系,以及解码如何从比特中重建图像。大多数编解码器遵循相同的核心思想,但它们使用不同的方法和技术。它们支持更多的块大小、额外的预测模式、各种类型的变换、不同的编码算法,并且通常包括一个后处理流水线来完善最终图像。
显而易见的结论是,现代编解码器更复杂(有时更慢),但它们通常产生更好的结果。然而,“更好”并不总是容易定义。一些问题仍然存在:编解码器复杂性与输出质量之间有何权衡?以及在不同情况下,哪些编解码器效果最好?