JavaScript 类型化数组
JavaScript 类型化数组是类数组对象,它提供了一种在内存缓冲区中读写原始二进制数据的机制。
类型化数组不旨在取代任何功能的常规数组。相反,它们为开发人员提供了一个熟悉的接口来操作二进制数据。这在与平台功能交互时非常有用,例如音频和视频操作、使用 WebSockets 访问原始数据等等。JavaScript 类型化数组中的每个条目都是一个原始二进制值,其格式支持多种,从 8 位整数到 64 位浮点数。
类型化数组对象与具有相似语义的数组共享许多相同的方法。但是,类型化数组**不应**与普通数组混淆,因为对类型化数组调用 Array.isArray() 会返回 false。此外,并非所有适用于普通数组的方法都受类型化数组支持(例如,push 和 pop)。
为了实现最大的灵活性和效率,JavaScript 类型化数组将实现分为**缓冲区**和**视图**。缓冲区是表示数据块的对象;它没有可言说的格式,也无法访问其内容。为了访问缓冲区中包含的内存,您需要使用视图。视图提供了一个**上下文**——即数据类型、起始偏移量和元素数量。
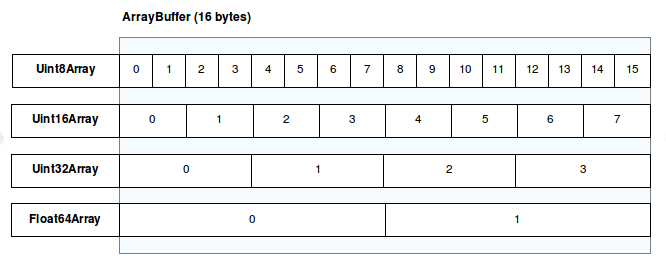
缓冲区
有两种类型的缓冲区:ArrayBuffer 和 SharedArrayBuffer。两者都是内存跨度的低级表示。它们的名称中带有“数组”,但它们与数组没有太多关系——您无法直接读写它们。相反,缓冲区是只包含原始数据的通用对象。为了访问缓冲区表示的内存,您需要使用视图。
缓冲区支持以下操作
- **分配**:一旦创建了新缓冲区,就会分配新的内存跨度并将其初始化为
0。 - **复制**:使用
slice()方法,您可以高效地复制内存的一部分,而无需创建视图来手动复制每个字节。 - **传输**:使用
transfer()和transferToFixedLength()方法,您可以将内存跨度的所有权传输到新的缓冲区对象。这在不同执行上下文之间传输数据而无需复制时非常有用。传输后,原始缓冲区不再可用。SharedArrayBuffer无法传输(因为缓冲区已被所有执行上下文共享)。 - **调整大小**:使用
resize()方法,您可以调整内存跨度的大小(要么请求更多内存空间,只要不超过预设的maxByteLength限制,要么释放一些内存空间)。SharedArrayBuffer只能增长,不能缩小。
ArrayBuffer 和 SharedArrayBuffer 之间的区别在于,前者一次只能由一个执行上下文拥有。如果您将 ArrayBuffer 传递给不同的执行上下文,它将被**传输**,并且原始 ArrayBuffer 将变得不可用。这确保了在任何给定时间只有一个执行上下文可以访问内存。SharedArrayBuffer 在传递给不同的执行上下文时不会被传输,因此它可以同时被多个执行上下文访问。这可能会在多个线程访问同一内存跨度时引入竞态条件,因此 Atomics 方法等操作变得有用。
视图
目前主要有两种视图:类型化数组视图和 DataView。类型化数组提供了实用方法,允许您方便地转换二进制数据。DataView 更低级,允许对数据访问进行精细控制。使用这两种视图读写数据的方式非常不同。
这两种视图都会使 ArrayBuffer.isView() 返回 true。它们都具有以下属性
buffer-
视图引用的底层缓冲区。
byteOffset-
视图从其缓冲区起始位置开始的偏移量(以字节为单位)。
byteLength-
视图的长度(以字节为单位)。
两个构造函数都接受上述三个作为单独的参数,尽管类型化数组构造函数接受 length 作为元素数量而不是字节数量。
类型化数组视图
类型化数组视图具有自描述性名称,并为所有常见的数字类型(如 Int8、Uint32、Float64 等)提供视图。有一种特殊的类型化数组视图,Uint8ClampedArray,它将值限制在 0 到 255 之间。这对于 Canvas 数据处理非常有用,例如。
| 类型 | 值范围 | 字节大小 | Web IDL 类型 |
|---|---|---|---|
Int8Array |
-128 到 127 | 1 | byte |
Uint8Array |
0 到 255 | 1 | octet |
Uint8ClampedArray |
0 到 255 | 1 | octet |
Int16Array |
-32768 到 32767 | 2 | short |
Uint16Array |
0 到 65535 | 2 | unsigned short |
Int32Array |
-2147483648 到 2147483647 | 4 | long |
Uint32Array |
0 到 4294967295 | 4 | unsigned long |
Float16Array |
-65504 到 65504 |
2 | N/A |
Float32Array |
-3.4e38 到 3.4e38 |
4 | unrestricted float |
Float64Array |
-1.8e308 到 1.8e308 |
8 | unrestricted double |
BigInt64Array |
-263 到 263 - 1 | 8 | bigint |
BigUint64Array |
0 到 264 - 1 | 8 | bigint |
所有类型化数组视图都具有相同的由 TypedArray 类定义的方法和属性。它们仅在底层数据类型和字节大小上有所不同。这在值编码和规范化中进行了更详细的讨论。
类型化数组原则上是定长的,因此可能改变数组长度的数组方法不可用。这包括 pop、push、shift、splice 和 unshift。此外,flat 不可用,因为没有嵌套的类型化数组,并且包括 concat 和 flatMap 在内的相关方法没有很好的用例,因此不可用。由于 splice 不可用,toSpliced 也不可用。所有其他数组方法在 Array 和 TypedArray 之间共享。
另一方面,TypedArray 具有额外的 set 和 subarray 方法,可优化处理查看同一缓冲区的多个类型化数组。set() 方法允许使用来自另一个数组或类型化数组的数据一次设置多个类型化数组索引。如果两个类型化数组共享相同的底层缓冲区,则操作可能更高效,因为它是一个快速的内存移动。subarray() 方法创建一个新的类型化数组视图,该视图引用与原始类型化数组相同的缓冲区,但跨度更窄。
无法在不更改底层缓冲区的情况下直接更改类型化数组的长度。但是,当类型化数组查看可调整大小的缓冲区并且没有固定的 byteLength 时,它是**长度跟踪**的,并且会随着可调整大小的缓冲区调整大小而自动调整以适应底层缓冲区。有关详细信息,请参阅查看可调整大小缓冲区时的行为。
与常规数组类似,您可以使用方括号表示法访问类型化数组元素。检索底层缓冲区中相应的字节并将其解释为数字。任何使用数字(或数字的字符串表示,因为在访问属性时数字总是转换为字符串)的属性访问都将由类型化数组代理——它们从不与对象本身交互。这意味着,例如
- 越界索引访问总是返回
undefined,而不会实际访问对象上的属性。 - 任何尝试写入此类越界属性的操作都没有效果:它不会抛出错误,也不会更改缓冲区或类型化数组。
- 类型化数组索引似乎是可配置和可写入的,但任何尝试更改其属性的操作都将失败。
const uint8 = new Uint8Array([1, 2, 3]);
console.log(uint8[0]); // 1
// For illustrative purposes only. Not for production code.
uint8[-1] = 0;
uint8[2.5] = 0;
uint8[NaN] = 0;
console.log(Object.keys(uint8)); // ["0", "1", "2"]
console.log(uint8[NaN]); // undefined
// Non-numeric access still works
uint8[true] = 0;
console.log(uint8[true]); // 0
Object.freeze(uint8); // TypeError: Cannot freeze array buffer views with elements
DataView
DataView 是一个低级接口,提供 getter/setter API 来读取和写入缓冲区中的任意数据。这在处理不同类型的数据时非常有用。类型化数组视图是您平台的本机字节顺序(参见字节序)。使用 DataView,可以控制字节顺序。默认情况下,它是大端字节序——字节从最高有效位到最低有效位排序。可以使用 getter/setter 方法反转此顺序,使字节从最低有效位到最高有效位排序(小端字节序)。
DataView 不需要对齐;多字节读写可以从任何指定的偏移量开始。setter 方法以相同的方式工作。
以下示例使用 DataView 获取任何数字的二进制表示
function toBinary(
x,
{ type = "Float64", littleEndian = false, separator = " ", radix = 16 } = {},
) {
const bytesNeeded = globalThis[`${type}Array`].BYTES_PER_ELEMENT;
const dv = new DataView(new ArrayBuffer(bytesNeeded));
dv[`set${type}`](0, x, littleEndian);
const bytes = Array.from({ length: bytesNeeded }, (_, i) =>
dv
.getUint8(i)
.toString(radix)
.padStart(8 / Math.log2(radix), "0"),
);
return bytes.join(separator);
}
console.log(toBinary(1.1)); // 3f f1 99 99 99 99 99 9a
console.log(toBinary(1.1, { littleEndian: true })); // 9a 99 99 99 99 99 f1 3f
console.log(toBinary(20, { type: "Int8", radix: 2 })); // 00010100
使用类型化数组的 Web API
这些是一些使用类型化数组的 API 示例;还有其他,并且一直在添加。
FileReader.prototype.readAsArrayBuffer()-
FileReader.prototype.readAsArrayBuffer()方法开始读取指定Blob或File的内容。 fetch()-
fetch()的body选项可以是类型化数组或ArrayBuffer,使您能够将这些对象作为POST请求的有效负载发送。 ImageData.data-
是一个
Uint8ClampedArray,表示一个包含 RGBA 顺序数据的二维数组,整数值在0到255之间(包括)。
示例
将视图与缓冲区一起使用
首先,我们需要创建一个缓冲区,这里固定长度为 16 字节
const buffer = new ArrayBuffer(16);
此时,我们有一个所有字节都预初始化为 0 的内存块。但是,我们能做的并不多。例如,我们可以确认缓冲区的大小是否正确
if (buffer.byteLength === 16) {
console.log("Yes, it's 16 bytes.");
} else {
console.log("Oh no, it's the wrong size!");
}
在我们真正使用这个缓冲区之前,我们需要创建一个视图。让我们创建一个将缓冲区中的数据视为 32 位有符号整数数组的视图
const int32View = new Int32Array(buffer);
现在我们可以像普通数组一样访问数组中的字段
for (let i = 0; i < int32View.length; i++) {
int32View[i] = i * 2;
}
这用值 0、2、4 和 6 填充了数组中的 4 个条目(4 个条目,每个 4 字节,总共 16 字节)。
同一数据的多个视图
当您考虑可以在同一数据上创建多个视图时,事情开始变得非常有趣。例如,给定上面的代码,我们可以像这样继续
const int16View = new Int16Array(buffer);
for (let i = 0; i < int16View.length; i++) {
console.log(`Entry ${i}: ${int16View[i]}`);
}
这里我们创建一个 16 位整数视图,它与现有的 32 位视图共享相同的缓冲区,并将缓冲区中的所有值作为 16 位整数输出。现在我们得到输出 0、0、2、0、4、0、6、0(假设是小端编码)
Int16Array | 0 | 0 | 2 | 0 | 4 | 0 | 6 | 0 | Int32Array | 0 | 2 | 4 | 6 | ArrayBuffer | 00 00 00 00 | 02 00 00 00 | 04 00 00 00 | 06 00 00 00 |
不过,您可以更进一步。考虑一下
int16View[0] = 32;
console.log(`Entry 0 in the 32-bit array is now ${int32View[0]}`);
输出是 "32 位数组中的条目 0 现在是 32"。
换句话说,这两个数组确实在同一个数据缓冲区上查看,将其视为不同的格式。
Int16Array | 32 | 0 | 2 | 0 | 4 | 0 | 6 | 0 | Int32Array | 32 | 2 | 4 | 6 | ArrayBuffer | 20 00 00 00 | 02 00 00 00 | 04 00 00 00 | 06 00 00 00 |
您可以对任何视图类型执行此操作,尽管如果您设置一个整数然后将其读取为浮点数,您可能会得到一个奇怪的结果,因为位被解释的方式不同。
const float32View = new Float32Array(buffer);
console.log(float32View[0]); // 4.484155085839415e-44
从缓冲区读取文本
缓冲区不总是表示数字。例如,读取文件可以为您提供文本数据缓冲区。您可以使用类型化数组从缓冲区中读取此数据。
以下使用 TextDecoder Web API 读取 UTF-8 文本
const buffer = new ArrayBuffer(8);
const uint8 = new Uint8Array(buffer);
// Data manually written here, but pretend it was already in the buffer
uint8.set([228, 189, 160, 229, 165, 189]);
const text = new TextDecoder().decode(uint8);
console.log(text); // "你好"
以下使用 String.fromCharCode() 方法读取 UTF-16 文本
const buffer = new ArrayBuffer(8);
const uint16 = new Uint16Array(buffer);
// Data manually written here, but pretend it was already in the buffer
uint16.set([0x4f60, 0x597d]);
const text = String.fromCharCode(...uint16);
console.log(text); // "你好"
处理复杂数据结构
通过将单个缓冲区与多个不同类型的视图结合起来,从缓冲区中不同的偏移量开始,您可以与包含多种数据类型的数据对象交互。这使您例如可以与 WebGL 或数据文件中的复杂数据结构交互。
考虑这个 C 结构
struct someStruct {
unsigned long id;
char username[16];
float amountDue;
};
您可以像这样访问包含此格式数据的缓冲区
const buffer = new ArrayBuffer(24);
// … read the data into the buffer …
const idView = new Uint32Array(buffer, 0, 1);
const usernameView = new Uint8Array(buffer, 4, 16);
const amountDueView = new Float32Array(buffer, 20, 1);
然后您可以访问,例如,使用 amountDueView[0] 访问应付款。
**注意:** C 结构中的数据结构对齐是平台相关的。请注意并考虑这些填充差异。
转换为普通数组
处理类型化数组后,有时将其转换回普通数组以受益于 Array 原型很有用。这可以通过使用 Array.from() 来完成
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = Array.from(typedArray);
以及展开语法
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = [...typedArray];
另见
- 使用类型化数组更快地操作 Canvas 像素 (hacks.mozilla.org, 2011)
- 类型化数组 - 浏览器中的二进制数据 (web.dev, 2012)
- 字节序
ArrayBufferDataViewTypedArraySharedArrayBuffer