Streams API 概念
The Streams API 为 Web 平台增加了一套非常有用的工具,提供了对象,让 JavaScript 可以以编程方式访问通过网络接收的数据流,并按开发者期望的方式进行处理。与流相关的一些概念和术语可能对您来说是新的 — 本文将解释您需要知道的一切。
可读流
可读流 (Readable stream) 是一个数据源,在 JavaScript 中由一个 ReadableStream 对象表示,它来自一个底层源 (underlying source) — 这是网络上或其他域中的某个资源,您想从中获取数据。
底层源有两种类型
块 (Chunks)
数据以称为块 (chunks) 的小块形式按顺序读取。一个块可以是一个字节,也可以是更大的东西,例如一个特定大小的类型化数组 (typed array)。单个流可以包含不同大小和类型的块。
放入流中的块被称为已入队 (enqueued) — 这意味着它们在队列中等待读取。内部队列 (internal queue) 会跟踪尚未读取的块(请参阅下面的“内部队列和排队策略”部分)。
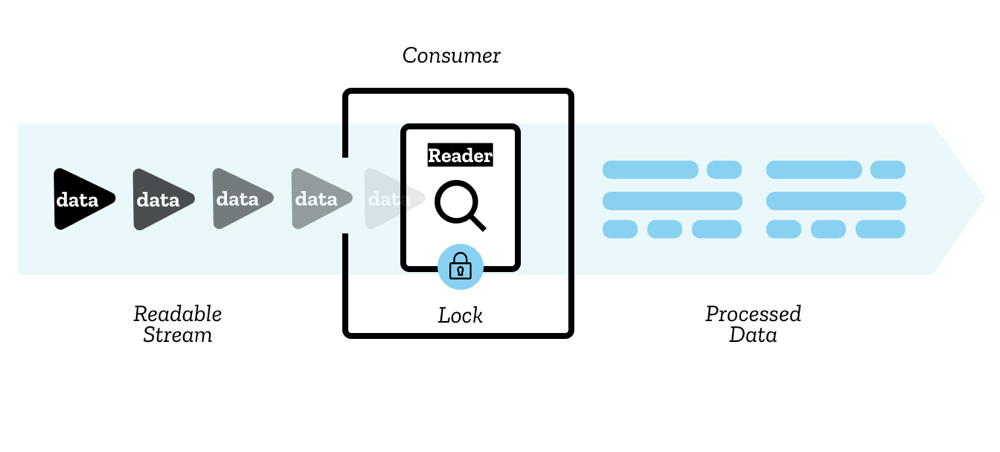
读取器、消费者和控制器
流中的块由读取器 (reader) 读取 — 它一次处理一个块的数据,允许您对其执行任何您想做的操作。读取器以及与之相关的其他处理代码称为消费者 (consumer)。
还有一个您将使用的构造称为控制器 (controller) — 每个读取器都有一个关联的控制器,允许您控制流(例如,如果您愿意,可以关闭它)。
锁定
一次只有一个读取器可以读取一个流;当创建一个读取器并开始读取一个流(一个活动读取器 (active reader))时,我们说它被锁定 (locked) 到该流。如果您想让另一个读取器开始读取您的流,您通常需要在做其他事情之前取消第一个读取器(尽管您可以分流 (tee) 流,请参阅下面的“分流”部分)。
可读流和字节流
请注意,可读流有两种不同的类型。除了常规的可读流之外,还有一种称为字节流 (byte stream) 的类型 — 它是用于读取底层字节源的常规流的扩展版本。与常规可读流相比,字节流允许由 BYOB 读取器(BYOB,“bring your own buffer”,自带缓冲区)读取。这种读取器允许流直接读取到开发者提供的缓冲区中,从而最大限度地减少所需的复制。您的代码将使用哪个底层流(以及因此的读取器和控制器)取决于流最初是如何创建的(请参阅 ReadableStream() 构造函数页面)。
您可以通过诸如 fetch 请求的 Response.body 之类的机制来利用现成的可读流,或者使用 ReadableStream() 构造函数来创建您自己的流。
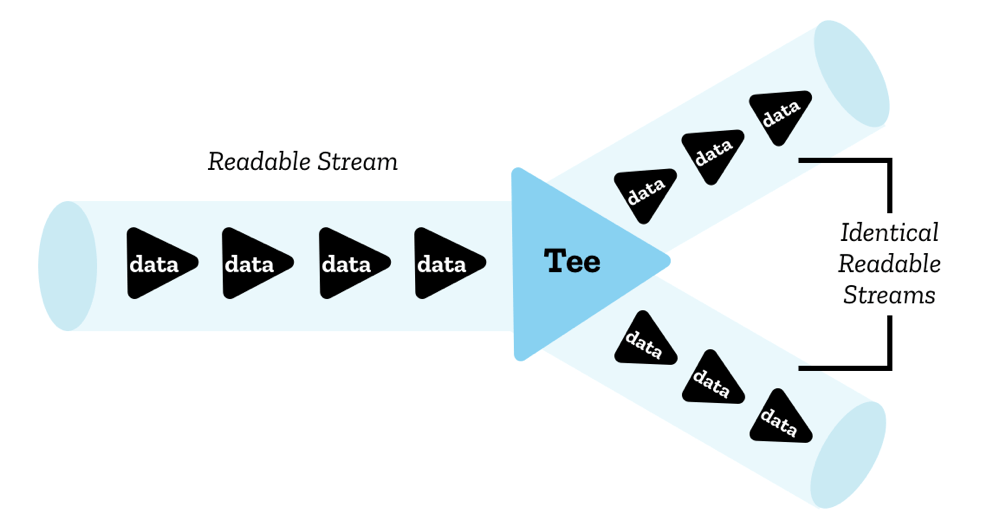
分流 (Teeing)
即使一次只有一个读取器可以读取一个流,也可以将一个流分割成两个相同的副本,然后由两个独立的读取器读取。这称为分流 (teeing)。
在 JavaScript 中,这通过 ReadableStream.tee() 方法实现 — 它会输出一个包含原始可读流的两个相同副本的数组,然后可以由两个独立的读取器独立读取。
例如,您可以在 ServiceWorker 中这样做,如果您想将服务器响应流式传输到浏览器,同时也将它流式传输到 ServiceWorker 缓存。由于响应体不能被消耗多次,而且一个流不能被多个读取器同时读取,所以您需要两个副本才能做到这一点。
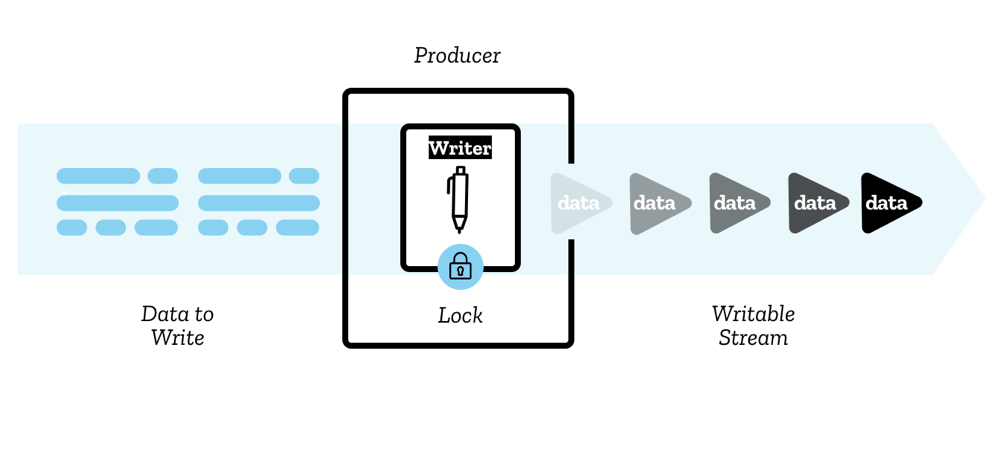
可写流
可写流 (Writable stream) 是您可以向其中写入数据的目标,在 JavaScript 中由一个 WritableStream 对象表示。这充当了底层接收器 (underlying sink) 之上的抽象 — 一个用于写入原始数据的低级 I/O 接收器。
数据通过写入器 (writer) 一次一个块地写入流。一个块可以采取多种形式,就像读取器中的块一样。您可以使用任何您喜欢的代码来生成准备写入的块;写入器加上相关的代码称为生产者 (producer)。
当创建一个写入器并开始向流写入(一个活动写入器 (active writer))时,我们说它被锁定 (locked) 到该流。一次只有一个写入器可以写入可写流。如果您想让另一个写入器开始写入您的流,您通常需要在附加另一个写入器之前中止它。
内部队列 (internal queue) 会跟踪已写入流但尚未被底层接收器处理的块。
还有一个您将使用的构造称为控制器 — 每个写入器都有一个关联的控制器,允许您控制流(例如,如果您愿意,可以中止它)。
您可以使用 WritableStream() 构造函数来利用可写流。目前它们在浏览器中的可用性非常有限。
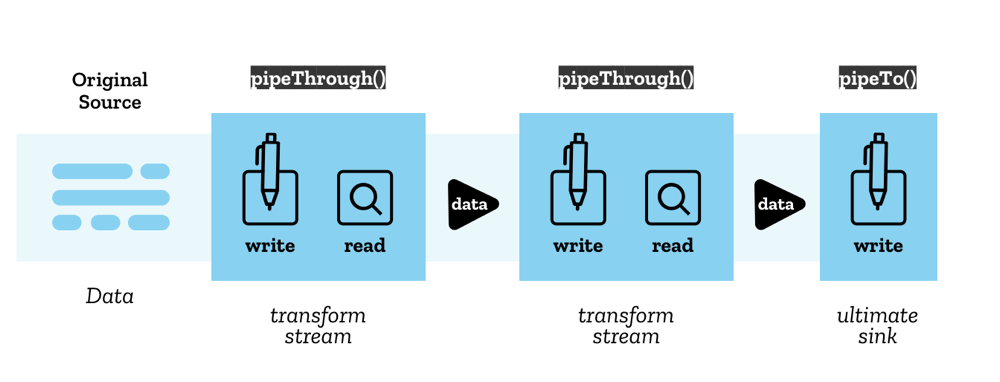
管道链
Streams API 允许使用称为管道链 (pipe chain) 的结构将流管道连接在一起。有两种方法可以实现这一点
-
ReadableStream.pipeThrough()— 将流通过转换流 (transform stream) 进行管道传输,沿途可能转换数据格式。例如,这可能用于编码或解码视频帧、压缩或解压缩数据,或以其他方式将数据从一种形式转换为另一种形式。转换流由一对流组成:一个用于读取数据的可读流和一个用于写入数据的可写流,以及适当的机制来确保在数据写入后立即提供新数据以供读取。
TransformStream是转换流的具体实现,但任何具有相同可读流和可写流属性的对象都可以传递给pipeThrough()。 -
ReadableStream.pipeTo()— 将数据管道传输到一个作为管道链终点的可写流。
管道链的开头称为原始源 (original source),结尾称为最终接收器 (ultimate sink)。
背压
流中的一个重要概念是背压 (backpressure) — 这是单个流或管道链调节读取/写入速度的过程。当链中后面的流仍然繁忙且尚未准备好接受更多块时,它会向后发送信号,指示前面的转换流(或原始源)减慢传输速度,这样就不会在任何地方产生瓶颈。
要在 ReadableStream 中使用背压,我们可以通过查询控制器上的 ReadableStreamDefaultController.desiredSize 属性,来询问控制器想要的块大小。如果太低,我们的 ReadableStream 可以告诉它的底层源停止发送数据,然后我们沿着流链施加背压。
如果稍后消费者再次想要接收数据,我们可以使用流创建中的 pull 方法来告诉我们的底层源向我们的流提供数据。
内部队列和排队策略
如前所述,流中尚未处理完的块由内部队列跟踪。
- 对于可读流,这些是已入队但尚未读取的块。
- 对于可写流,这些是已写入但尚未被底层接收器处理的块。
内部队列采用排队策略 (queuing strategy),它决定如何根据内部队列状态来发出背压信号。
通常,该策略将队列中块的大小与一个称为高水位线 (high water mark) 的值进行比较,这是队列倾向于管理的最大的总块大小。
执行的计算是
高水位线 - 队列中块的总大小 = 期望大小
期望大小 (desired size) 是流仍然可以接受的块数,以保持流的流动但大小低于高水位线。块的生成将根据需要减慢/加快,以使流尽可能快地流动,同时保持期望大小大于零。如果该值降至零(或更低),则意味着块的生成速度快于流的处理能力,这可能会导致问题。
例如,假设块大小为 1,高水位线为 3。这意味着最多可以入队 3 个块,然后达到高水位线并施加背压。