Web Audio API 背后的基本概念
本文解释了 Web Audio API 功能背后的一些音频理论,旨在帮助您在设计应用程序如何路由音频时做出明智的决定。如果您还不是一名音响工程师,它将为您提供足够的背景知识,让您理解 Web Audio API 的工作原理。
音频图
Web Audio API 涉及在音频上下文中处理音频操作,并且被设计为允许模块化路由。每个音频节点执行一个基本音频操作,并与一个或多个其他音频节点链接,以形成一个音频路由图。支持多种具有不同通道布局的源,甚至可以在单个上下文中。这种模块化设计提供了灵活性,可以创建具有动态效果的复杂音频功能。
音频节点通过它们的输入和输出连接起来,形成一个链,这个链以一个或多个源开始,经过一个或多个节点,然后到达一个目的地(尽管如果您只想可视化一些音频数据,您不必提供目的地)。一个简单、典型的 Web 音频工作流程如下所示:
- 创建音频上下文。
- 在上下文中创建音频源(例如
<audio>、振荡器或流)。 - 创建音频效果(例如混响、二阶滤波器、声像器或压缩器节点)。
- 选择音频的最终目的地(例如用户的电脑扬声器)。
- 将源节点连接到零个或多个效果节点,然后连接到所选目的地。
注意:通道表示法是一个数值,例如 2.0 或 5.1,表示信号中可用音频通道的数量。第一个数字是信号包含的全频段音频通道数量。小数点后的数字表示为低频效果 (LFE) 输出保留的通道数量;这些通常被称为 低音炮。

每个输入或输出都由一个或多个音频通道组成,它们共同代表特定的音频布局。支持任何离散通道结构,包括单声道、立体声、四声道、5.1声道等。
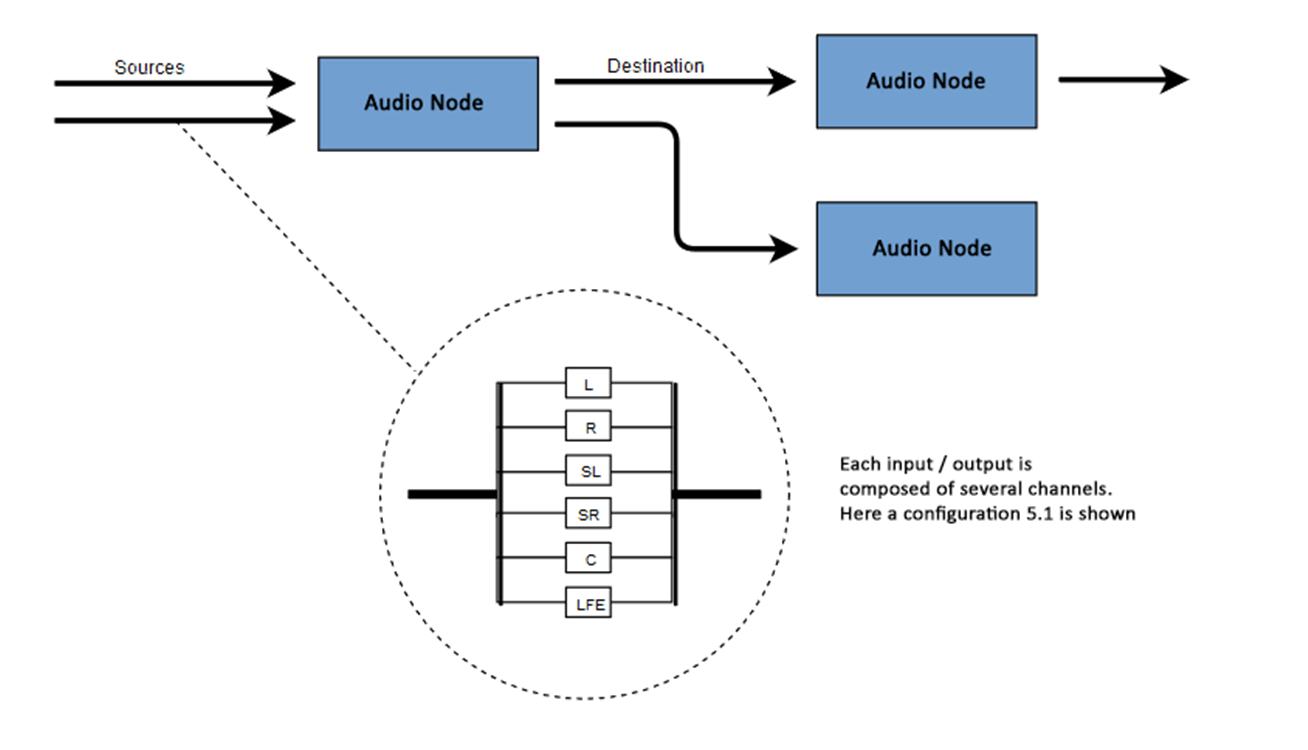
您有几种获取音频的方式
- 声音可以通过音频节点(例如振荡器)直接在 JavaScript 中生成。
- 它可以从原始 PCM 数据创建(例如 .WAV 文件或
decodeAudioData()支持的其他格式)。 - 它可以从 HTML 媒体元素生成,例如
<video>或<audio>。 - 它可以从 WebRTC
MediaStream获取,例如网络摄像头或麦克风。
音频数据:样本中的内容
当音频信号被处理时,会发生采样。采样是将连续信号转换为离散信号的过程。换句话说,连续声波(例如现场演奏的乐队)被转换为一系列数字样本(离散时间信号),这使得计算机能够以离散块处理音频。
您可以在维基百科页面 采样(信号处理) 上找到更多信息。
音频缓冲区:帧、样本和通道
AudioBuffer 由三个参数定义
- 通道数(单声道为 1,立体声为 2 等),
- 其长度,即缓冲区内的采样帧数,
- 以及采样率,即每秒播放的采样帧数。
一个样本是一个 32 位浮点值,表示特定通道(如果是立体声,则为左声道或右声道)中每个特定时间点的音频流值。一个帧或采样帧是所有通道在特定时间点播放的所有值的集合:所有通道在同一时间播放的所有样本(立体声为两个,5.1 声道为六个等)。
采样率是这些样本(或帧,因为一帧中的所有样本同时播放)在一秒钟内播放的数量,以赫兹 (Hz) 为单位测量。采样率越高,音质越好。
我们来看一个单声道和立体声音频缓冲区,每个都长一秒,采样率为 44100Hz
- 单声道缓冲区将有 44,100 个样本和 44,100 个帧。
length属性将为 44,100。 - 立体声缓冲区将有 88,200 个样本,但仍有 44,100 个帧。
length属性仍为 44100,因为它等于帧数。

当缓冲区播放时,您将首先听到最左边的采样帧,然后是紧邻它的帧,然后是下一个,依此类推,直到缓冲区结束。在立体声情况下,您将同时听到两个通道。采样帧很方便,因为它们独立于通道数,并以理想的方式表示时间,适用于精确的音频操作。
注意:要从帧数获取秒数,请将帧数除以采样率。要从样本数获取帧数,您只需将后者除以通道数。
这里有几个简单的例子
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 2,
length: 22050,
sampleRate: 44100,
});
注意:在数字音频中,44,100 Hz(或表示为44.1 kHz)是一种常见的采样频率。为什么是 44.1 kHz?
首先,因为人耳的听力范围大致在 20 Hz 到 20,000 Hz 之间。根据奈奎斯特-香农采样定理,采样频率必须大于要重现的最大频率的两倍。因此,采样率必须大于 40,000 Hz。
其次,在采样之前必须对信号进行低通滤波,否则会发生混叠。虽然理想的低通滤波器可以完美地通过 20 kHz 以下的频率(不衰减它们)并完美地截止 20 kHz 以上的频率,但在实践中,需要一个过渡带,其中频率部分衰减。过渡带越宽,制作抗混叠滤波器就越容易和经济。44.1 kHz 的采样频率允许 2.05 kHz 的过渡带。
如果您使用上述调用,您将获得一个双声道立体声缓冲区,当在以 44100 Hz 运行的 AudioContext(非常常见,大多数普通声卡都以该速率运行)上播放时,它将持续 0.5 秒:22,050 帧/44,100 Hz = 0.5 秒。
const context = new AudioContext();
const buffer = new AudioBuffer(context, {
numberOfChannels: 1,
length: 22050,
sampleRate: 22050,
});
如果您使用此调用,您将获得一个单声道缓冲区(单通道缓冲区),当在以 44,100 Hz 运行的 AudioContext 上播放时,它将自动重新采样到 44,100 Hz(因此产生 44,100 帧),并持续 1.0 秒:44,100 帧/44,100 Hz = 1 秒。
注意:音频重采样与图像大小调整非常相似。假设您有一张 16 x 16 的图像,但想让它填充 32 x 32 的区域。您对其进行大小调整(或重采样)。结果质量较低(根据大小调整算法,它可能会模糊或边缘化),但它有效,调整大小后的图像占用空间更少。重采样音频也是如此:您节省了空间,但实际上,您无法正确再现高频内容或高音。
平面式缓冲区与交错式缓冲区
Web Audio API 使用平面式缓冲区格式。左右声道存储方式如下
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (for a buffer of 16 frames)
这种结构在音频处理中非常普遍,使得独立处理每个通道变得容易。
另一种方法是使用交错式缓冲区格式
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (for a buffer of 16 frames)
这种格式在不进行太多处理的情况下存储和播放音频时很常见,例如:.WAV 文件或解码后的 MP3 流。
由于 Web Audio API 旨在用于处理,因此它只公开平面式缓冲区。它使用平面格式,但在将音频发送到声卡进行播放时将其转换为交错格式。相反,当 API 解码 MP3 时,它从交错格式开始,并将其转换为平面格式进行处理。
音频通道
每个音频缓冲区可能包含不同数量的通道。大多数现代音频设备使用基本的单声道(只有一个通道)和立体声(左声道和右声道)设置。一些更复杂的设置支持环绕声设置(如四声道和5.1声道),这些设置由于其高通道数而可以带来更丰富的音效体验。我们通常使用下表中详细的标准缩写来表示通道
| 名称 | 渠道 |
|---|---|
| 单声道 | 0: M: 单声道 |
| 立体声 | 0: L: 左 1: R: 右 |
| 四声道 | 0: L: 左 1: R: 右 2: SL: 左环绕 3: SR: 右环绕 |
| 5.1 | 0: L: 左 1: R: 右 2: C: 中置 3: LFE: 低音炮 4: SL: 左环绕 5: SR: 右环绕 |
上混和下混
当输入和输出的通道数不匹配时,必须进行上混或下混。以下规则通过将 AudioNode.channelInterpretation 属性设置为 speakers 或 discrete 来控制
| 解释 | 输入通道 | 输出通道 | 混合规则 |
|---|---|---|---|
扬声器 |
1 (单声道) |
2 (立体声) |
从单声道上混到立体声.M 输入通道用于两个输出通道(L 和 R)。output.L = input.M
|
1 (单声道) |
4 (四声道) |
从单声道上混到四声道。M 输入通道用于非环绕声输出通道(L 和 R)。环绕声输出通道(SL 和 SR)是静音的。output.L = input.M
|
|
1 (单声道) |
6 (5.1) |
从单声道上混到 5.1 声道。M 输入通道用于中置输出通道(C)。所有其他通道(L、R、LFE、SL 和 SR)是静音的。output.L = 0output.C = input.M
|
|
2 (立体声) |
1 (单声道) |
从立体声下混到单声道. 两个输入通道( L 和 R)以相同比例组合,产生唯一的输出通道(M)。output.M = 0.5 * (input.L + input.R)
|
|
2 (立体声) |
4 (四声道) |
从立体声上混到四声道。L 和 R 输入通道用于各自的非环绕声输出通道(L 和 R)。环绕声输出通道(SL 和 SR)是静音的。output.L = input.L
|
|
2 (立体声) |
6 (5.1) |
从立体声上混到 5.1 声道。L 和 R 输入通道用于各自的非环绕声输出通道(L 和 R)。环绕声输出通道(SL 和 SR),以及中置(C)和低音炮(LFE)通道,都保持静音。output.L = input.L
|
|
4 (四声道) |
1 (单声道) |
从四声道下混到单声道. 所有四个输入通道( L、R、SL 和 SR)以相同比例组合,产生唯一的输出通道(M)。output.M = 0.25 * (input.L + input.R + input.SL + input.SR)
|
|
4 (四声道) |
2 (立体声) |
从四声道下混到立体声. 两个左输入通道( L 和 SL)以相同比例组合,产生唯一的左输出通道(L)。同样,两个右输入通道(R 和 SR)以相同比例组合,产生唯一的右输出通道(R)。output.L = 0.5 * (input.L + input.SL)output.R = 0.5 * (input.R + input.SR)
|
|
4 (四声道) |
6 (5.1) |
从四声道上混到 5.1 声道。L、R、SL 和 SR 输入通道用于各自的输出通道(L 和 R)。中置(C)和低音炮(LFE)通道保持静音。output.L = input.Loutput.R = input.Routput.C = 0output.LFE = 0output.SL = input.SLoutput.SR = input.SR
|
|
6 (5.1) |
1 (单声道) |
从 5.1 声道下混到单声道。 左声道( L 和 SL)、右声道(R 和 SR)和中置声道都混合在一起。环绕声道略微衰减,常规侧声道通过乘以 √2/2 进行功率补偿,使其算作单个声道。低音炮(LFE)声道丢失。output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
|
|
6 (5.1) |
2 (立体声) |
从 5.1 声道下混到立体声。 中置声道( C)与每个侧环绕声道(SL 或 SR)相加,并混合到每个侧声道。由于它被下混到两个声道,因此以较低的功率混合:在每种情况下,它都乘以 √2/2。低音炮(LFE)声道丢失。output.L = input.L + 0.7071 * (input.C + input.SL)output.R = input.R + 0.7071 * (input.C + input.SR)
|
|
6 (5.1) |
4 (四声道) |
从 5.1 声道下混到四声道。 中置( C)与侧面非环绕声道(L 和 R)混合。由于它被下混到两个声道,因此以较低的功率混合:在每种情况下,它都乘以 √2/2。环绕声道保持不变。低音炮(LFE)声道丢失。output.L = input.L + 0.7071 * input.Coutput.R = input.R + 0.7071 * input.Coutput.SL = input.SLoutput.SR = input.SR
|
|
| 其他非标准布局 | 非标准通道布局的行为与将 channelInterpretation 设置为 discrete 时的行为相同。规范明确允许未来定义新的扬声器布局。因此,这种回退不是面向未来的,因为浏览器对特定通道数的行为在未来可能会改变。 |
||
离散 |
任意 (x) |
任意 (y),其中 x<y |
上混离散通道。 用其对应的输入通道填充每个输出通道 — 即,具有相同索引的输入通道。没有对应输入通道的通道保持静音。 |
任意 (x) |
任意 (y),其中 x>y |
下混离散通道。 用其对应的输入通道填充每个输出通道 — 即,具有相同索引的输入通道。没有对应输出通道的输入通道将被丢弃。 |
|
可视化
通常,我们随时间获取输出以生成音频可视化,通常读取其增益或频率数据。然后,使用图形工具,我们将获得的数据转换为视觉表示,例如图形。Web Audio API 提供了一个 AnalyserNode,它不会改变通过它的音频信号。此外,它会输出音频数据,允许我们通过诸如 <canvas> 等技术对其进行处理。

您可以使用以下方法获取数据
AnalyserNode.getFloatFrequencyData()-
将当前频率数据复制到传入的
Float32Array数组中。 AnalyserNode.getByteFrequencyData()-
将当前频率数据复制到传入的
Uint8Array(无符号字节数组)中。 AnalyserNode.getFloatTimeDomainData()-
将当前波形或时域数据复制到传入的
Float32Array数组中。 AnalyserNode.getByteTimeDomainData()-
将当前波形或时域数据复制到传入的
Uint8Array(无符号字节数组)中。
注意:有关更多信息,请参阅我们的使用 Web Audio API 进行可视化文章。
空间化
音频空间化允许我们模拟音频信号在物理空间中某个点的位置和行为,模拟听众听到该音频。在 Web Audio API 中,空间化由 PannerNode 和 AudioListener 处理。
声像器使用右手笛卡尔坐标系来描述音频源的位置作为向量,以及其方向作为 3D 方向锥。锥体可以非常大,例如,对于全向声源。

同样,Web Audio API 使用右手笛卡尔坐标系描述听众:其位置作为向量,其方向作为两个方向向量,向上和向前。这些向量定义了听众头顶的方向和听众鼻子指向的方向。这些向量相互垂直。
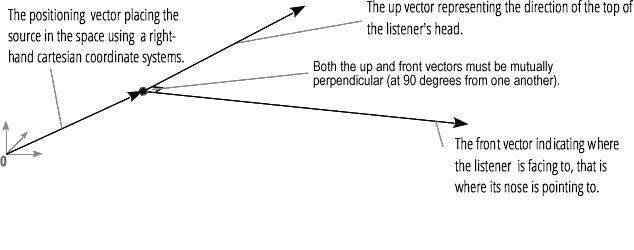
注意:有关更多信息,请参阅我们的Web 音频空间化基础文章。
扇入和扇出
在音频术语中,扇入描述了 ChannelMergerNode 接收一系列单声道输入源并输出单个多通道信号的过程

扇出描述了相反的过程,即 ChannelSplitterNode 接收多通道输入源并输出多个单声道输出信号
