find.find()
在标签页中搜索文本。
您可以使用此函数搜索常规的 HTTP(S) 网页。它搜索单个标签页:您可以指定要搜索的特定标签页的 ID,否则默认搜索活动标签页。它会搜索标签页中的所有框架。
您可以使搜索区分大小写,并使其仅匹配整个单词。
默认情况下,该函数仅返回找到的匹配项数量。通过传入 includeRangeData 和 includeRectData 选项,您可以获取有关目标标签页中匹配项位置的更多信息。
此函数将结果存储在内部,因此下次任何扩展程序调用 find.highlightResults() 时,此次 find 调用将突出显示其结果,直到下次有人调用 find()。
这是一个异步函数,返回一个 Promise。
语法
browser.find.find(
queryPhrase, // string
options // optional object
)
参数
options可选-
object。一个指定附加选项的对象。它可以包含以下任意属性,所有属性都是可选的。caseSensitive-
boolean。如果为true,则搜索区分大小写。默认为false。 entireWord-
boolean。仅匹配整个单词:因此,“Tok”不会在“Tokyo”中匹配。默认为false。 includeRangeData-
boolean。在响应中包含 range 数据,它描述了在页面 DOM 中找到匹配项的位置。默认为false。 includeRectData-
boolean。在响应中包含 rect 数据,它描述了在渲染页面中找到匹配项的位置。默认为false。 matchDiacritics-
boolean。如果为true,则搜索区分带重音符号的字母及其基本字母。例如,当设置为true时,搜索“résumé”不会匹配“resume”。默认为false。 tabId-
integer。要搜索的标签页的 ID。默认为活动标签页。
queryPhrase-
string。要搜索的文本。
返回值
一个 Promise,它将以包含最多三个属性的对象来 fulfilled。
计数-
integer。找到的结果数量。 rangeData可选-
array。如果在options参数中指定了includeRangeData,则将包含此属性。它以RangeData对象数组的形式提供,每个匹配项一个。每个RangeData对象描述了在 DOM 树中找到匹配项的位置。例如,这可以使扩展程序获取每个匹配项周围的文本,以便为匹配项显示上下文。项目对应于
rectData中提供的项目,因此rangeData[i]描述的匹配项与rectData[i]相同。每个
RangeData包含以下属性:endOffset-
匹配项在其文本节点中的结束位置。
endTextNodePos-
匹配项结束的文本节点的顺序位置。
framePos-
包含匹配项的框架的索引。0 对应于父窗口。请注意,
rangeData数组中对象的顺序将按帧索引的顺序依次排列:例如,第一系列rangeData对象的framePos将是 0,下一系列的framePos将是 1,依此类推。 起始偏移-
匹配项在其文本节点中的开始位置。
startTextNodePos-
匹配项开始的文本节点的顺序位置。
rectData可选-
array。如果在options参数中指定了includeRectData,则将包含此属性。它是一个RectData对象数组。它包含搜索中匹配的所有文本的客户端矩形,相对于视口左上角。扩展程序可以使用此来为结果提供自定义高亮显示。每个
RectData对象包含单个匹配项的矩形数据。它有两个属性:rectsAndTexts-
一个包含两个属性的对象,两者都是数组:
rectList:一个对象数组,每个对象都有四个整数属性:top、left、bottom、right。这些描述了相对于视口左上角的矩形。textList:一个字符串数组,对应于rectList数组。textList[i]中的条目包含由rectList[i]中的矩形所界定的匹配项部分。
例如,考虑网页的一部分如下所示:

如果搜索“You may”,则匹配项需要由两个矩形描述:

在这种情况下,在描述此匹配项的
RectData中,rectsAndTexts.rectList和rectsAndTexts.textList都将有 2 个项目。textList[0]将包含“You ”,而rectList[0]将包含其边界矩形。textList[1]将包含“may”,而rectList[1]将包含其边界矩形。
文本-
匹配项的完整文本,“You may”,如上例所示。
示例
基本示例
在活动标签页中搜索“banana”,记录匹配项数量,并突出显示它们。
function found(results) {
console.log(`There were: ${results.count} matches.`);
if (results.count > 0) {
browser.find.highlightResults();
}
}
browser.find.find("banana").then(found);
在所有标签页中搜索“banana”(请注意,这需要“tabs” 权限或匹配的 主机权限,因为它访问 tab.url)。
async function findInAllTabs(allTabs) {
for (const tab of allTabs) {
const results = await browser.find.find("banana", { tabId: tab.id });
console.log(`In page "${tab.url}": ${results.count} matches.`);
}
}
browser.tabs.query({}).then(findInAllTabs);
使用 rangeData
在此示例中,扩展程序使用 rangeData 来获取找到匹配项的上下文。上下文是包含匹配项的节点的完整 textContent。如果匹配项跨越节点,则上下文是所有跨越节点的 textContent 的串联。
请注意,为简单起见,此示例不处理包含框架的页面。要支持这一点,您需要将 rangeData 分组,每帧一组,并在每个框架中执行脚本。
后台脚本
// background.js
async function getContexts(matches) {
// get the active tab ID
const activeTabArray = await browser.tabs.query({
active: true,
currentWindow: true,
});
const tabId = activeTabArray[0].id;
// execute the content script in the active tab
await browser.tabs.executeScript(tabId, { file: "get-context.js" });
// ask the content script to get the contexts for us
const contexts = await browser.tabs.sendMessage(tabId, {
ranges: matches.rangeData,
});
for (const context of contexts) {
console.log(context);
}
}
browser.browserAction.onClicked.addListener((tab) => {
browser.find.find("example", { includeRangeData: true }).then(getContexts);
});
内容脚本
/**
* Get all the text nodes into a single array
*/
function getNodes() {
const walker = document.createTreeWalker(
document,
window.NodeFilter.SHOW_TEXT,
null,
false,
);
const nodes = [];
while ((node = walker.nextNode())) {
nodes.push(node);
}
return nodes;
}
/**
* Gets all text nodes in the document, then for each match, return the
* complete text content of nodes that contained the match.
* If a match spanned more than one node, concatenate the textContent
* of each node.
*/
function getContexts(ranges) {
const contexts = [];
const nodes = getNodes();
for (const range of ranges) {
let context = nodes[range.startTextNodePos].textContent;
let pos = range.startTextNodePos;
while (pos < range.endTextNodePos) {
pos++;
context += nodes[pos].textContent;
}
contexts.push(context);
}
return contexts;
}
browser.runtime.onMessage.addListener((message, sender, sendResponse) => {
sendResponse(getContexts(message.ranges));
});
使用 rectData
在此示例中,扩展程序使用 rectData 来“屏蔽”匹配项,通过在它们的边界矩形上方添加黑色 DIV。
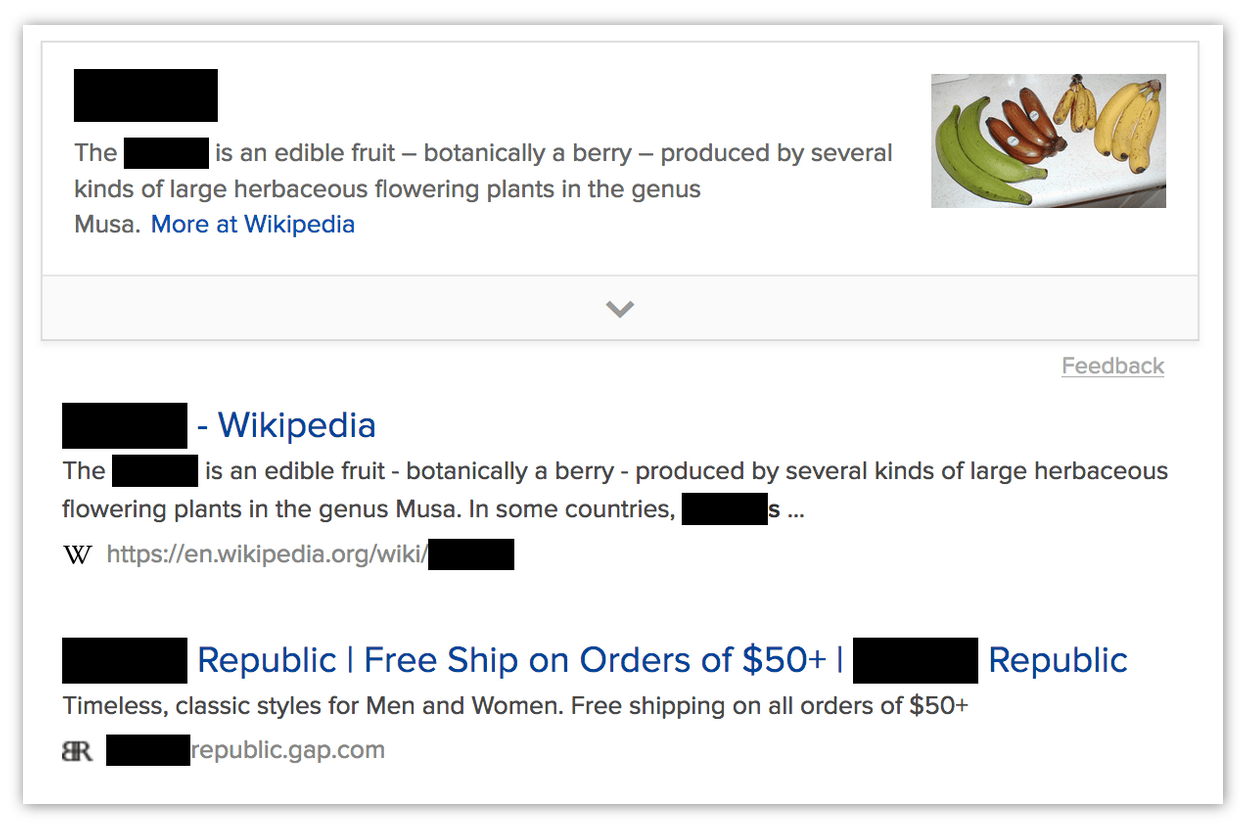
请注意,在许多方面,这是一种糟糕的屏蔽页面方式。
后台脚本
// background.js
async function redact(matches) {
// get the active tab ID
const activeTabArray = await browser.tabs.query({
active: true,
currentWindow: true,
});
const tabId = activeTabArray[0].id;
// execute the content script in the active tab
await browser.tabs.executeScript(tabId, { file: "redact.js" });
// ask the content script to redact matches for us
await browser.tabs.sendMessage(tabId, { rects: matches.rectData });
}
browser.browserAction.onClicked.addListener((tab) => {
browser.find.find("banana", { includeRectData: true }).then(redact);
});
内容脚本
// redact.js
/**
* Add a black DIV where the rect is.
*/
function redactRect(rect) {
const redaction = document.createElement("div");
redaction.style.backgroundColor = "black";
redaction.style.position = "absolute";
redaction.style.top = `${rect.top}px`;
redaction.style.left = `${rect.left}px`;
redaction.style.width = `${rect.right - rect.left}px`;
redaction.style.height = `${rect.bottom - rect.top}px`;
document.body.appendChild(redaction);
}
/**
* Go through every rect, redacting them.
*/
function redactAll(rectData) {
for (const match of rectData) {
for (const rect of match.rectsAndTexts.rectList) {
redactRect(rect);
}
}
}
browser.runtime.onMessage.addListener((message) => {
redactAll(message.rects);
});
扩展程序示例
浏览器兼容性
加载中…