WebGPU API
WebGPU API 使 Web 开发者能够使用底层系统的 GPU(图形处理器)执行高性能计算,并绘制可在浏览器中渲染的复杂图像。
WebGPU 是 WebGL 的后继者,它提供了与现代 GPU 更好的兼容性,支持通用 GPU 计算,更快的操作,以及访问更高级的 GPU 功能。
概念与用法
可以说,WebGL 在 2011 年左右首次出现后,在图形能力方面彻底改变了 Web。WebGL 是 OpenGL ES 2.0 图形库的 JavaScript 移植,允许网页将渲染计算直接传递给设备的 GPU,以极高的速度进行处理,并将结果渲染到 <canvas> 元素中。
WebGL 和用于编写 WebGL 着色器代码的 GLSL 语言很复杂,因此创建了几个 WebGL 库来简化 WebGL 应用程序的编写:流行的例子包括 Three.js、Babylon.js 和 PlayCanvas。开发者利用这些工具构建了沉浸式 Web 3D 游戏、音乐视频、培训和建模工具、VR 和 AR 体验等。
然而,WebGL 存在一些需要解决的根本问题
- 自 WebGL 发布以来,新一代原生 GPU API 已经出现——最流行的是 Microsoft 的 Direct3D 12、Apple 的 Metal 和 Khronos Group 的 Vulkan——它们提供了许多新功能。OpenGL(以及因此 WebGL)不再计划更新,因此它将无法获得这些新功能。另一方面,WebGPU 将不断添加新功能。
- WebGL 完全基于绘制图形并将其渲染到画布的使用场景。它不能很好地处理通用 GPU (GPGPU) 计算。GPGPU 计算对于许多不同的使用场景越来越重要,例如基于机器学习模型的场景。
- 3D 图形应用程序的要求越来越高,无论是同时渲染的对象数量,还是新渲染功能的使用。
WebGPU 解决了这些问题,提供了一个与现代 GPU API 兼容的更新的通用架构,感觉更“web 化”。它支持图形渲染,但也对 GPGPU 计算提供一流的支持。在 CPU 端渲染单个对象的成本显著降低,并且它支持现代 GPU 渲染功能,例如基于计算的粒子和后处理滤镜,如颜色效果、锐化和景深模拟。此外,它还可以直接在 GPU 上处理昂贵的计算,例如剔除和蒙皮模型变换。
通用模型
设备 GPU 和运行 WebGPU API 的 Web 浏览器之间有几个抽象层。在开始学习 WebGPU 时了解这些抽象层很有用
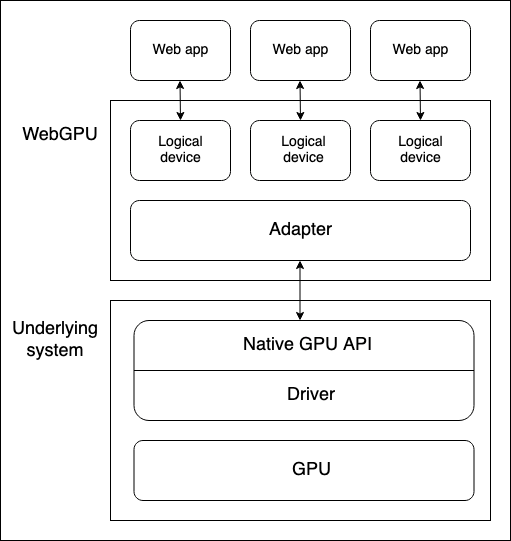
-
物理设备有 GPU。大多数设备只有一个 GPU,但有些设备有多个。有不同的 GPU 类型可用
- 集成 GPU,它与 CPU 在同一主板上,并共享其内存。
- 独立 GPU,它有自己的独立主板,与 CPU 分开。
- 在 CPU 上实现的软件“GPU”。
注意:上图假设设备只有一个 GPU。
-
原生 GPU API 是操作系统的一部分(例如 macOS 上的 Metal),它是一个编程接口,允许原生应用程序使用 GPU 的功能。API 指令通过驱动程序发送到 GPU(并接收响应)。一个系统可能拥有多个可用于与 GPU 通信的原生 OS API 和驱动程序,尽管上图假设设备只有一个原生 API/驱动程序。
-
浏览器的 WebGPU 实现通过原生 GPU API 驱动程序处理与 GPU 的通信。WebGPU 适配器在您的代码中有效地表示底层系统上可用的物理 GPU 和驱动程序。
-
逻辑设备是一种抽象,通过它单个 Web 应用程序可以以隔离的方式访问 GPU 功能。逻辑设备需要提供多路复用能力。物理设备的 GPU 同时被许多应用程序和进程使用,包括可能许多 Web 应用程序。每个 Web 应用程序需要能够独立访问 WebGPU,出于安全和逻辑原因。
访问设备
逻辑设备(由 GPUDevice 对象实例表示)是 Web 应用程序访问所有 WebGPU 功能的基础。访问设备如下
Navigator.gpu属性(如果您在 Worker 中使用 WebGPU 功能,则是WorkerNavigator.gpu)返回当前上下文的GPU对象。- 您通过
GPU.requestAdapter()方法访问适配器。此方法接受一个可选的设置对象,允许您请求例如高性能或低能耗适配器。如果未包含此对象,设备将提供对默认适配器的访问,这对于大多数用途来说已经足够。 - 可以通过
GPUAdapter.requestDevice()请求设备。此方法也接受一个选项对象(称为描述符),可用于指定逻辑设备应具有的精确功能和限制。如果未包含此对象,则提供的设备将具有合理的通用规范,这对于大多数用途来说已经足够。
结合一些功能检测检查,上述过程可以通过以下方式实现
async function init() {
if (!navigator.gpu) {
throw Error("WebGPU not supported.");
}
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
throw Error("Couldn't request WebGPU adapter.");
}
const device = await adapter.requestDevice();
// …
}
管线和着色器:WebGPU 应用程序结构
管线是一个逻辑结构,包含可编程阶段,用于完成程序的任务。WebGPU 目前能够处理两种类型的管线
-
渲染管线渲染图形,通常渲染到
<canvas>元素中,但它也可以在屏幕外渲染图形。它有两个主要阶段-
顶点阶段,其中顶点着色器接受输入到 GPU 的定位数据,并使用它通过应用指定的旋转、平移或透视等效果在 3D 空间中定位一系列顶点。然后,顶点被组装成三角形等基本图形(渲染图形的基本构建块),并由 GPU 进行光栅化,以确定每个三角形应覆盖绘图画布上的哪些像素。
-
片段阶段,其中片段着色器计算由顶点着色器生成的原始图形覆盖的每个像素的颜色。这些计算通常使用图像(以纹理形式)作为输入,提供表面细节以及虚拟光源的位置和颜色。
-
-
计算管线用于通用计算。计算管线包含一个计算阶段,其中计算着色器接受通用数据,在指定数量的工作组中并行处理,然后将结果返回到一个或多个缓冲区中。缓冲区可以包含任何类型的数据。
上面提到的着色器是由 GPU 处理的指令集。WebGPU 着色器使用一种低级 Rust 类语言编写,称为 WebGPU 着色语言 (WGSL)。
有几种不同的方法可以构建 WebGPU 应用程序,但该过程可能包含以下步骤
- 创建着色器模块:用 WGSL 编写着色器代码并将其打包到一个或多个着色器模块中。
- 获取并配置画布上下文:获取
<canvas>元素的webgpu上下文,并将其配置为从 GPU 逻辑设备接收要渲染的图形信息。如果您的应用程序没有图形输出,例如只使用计算管线的应用程序,则此步骤不是必需的。 - 创建包含数据的资源:您希望由管线处理的数据需要存储在 GPU 缓冲区或纹理中,以便您的应用程序可以访问。
- 创建管线:定义管线描述符,详细描述所需的管线,包括所需的数据结构、绑定、着色器和资源布局,然后从中创建管线。我们的基本演示只包含一个管线,但非平凡的应用程序通常会包含多个用于不同目的的管线。
- 运行计算/渲染通道:这涉及一些子步骤
- 创建命令编码器,它可以编码一组要传递给 GPU 执行的命令。
- 创建通道编码器对象,在其上发出计算/渲染命令。
- 运行命令以指定要使用的管线,从哪个缓冲区获取所需数据,要运行多少绘图操作(对于渲染管线),等等。
- 完成命令列表并将其封装在命令缓冲区中。
- 通过逻辑设备的命令队列将命令缓冲区提交给 GPU。
在下面的部分中,我们将研究一个基本的渲染管线演示,让您了解它需要什么。稍后,我们还将研究一个基本计算管线示例,了解它与渲染管线的区别。
基本渲染管线
在我们的基本渲染演示中,我们给一个<canvas>元素一个纯蓝色背景,并在其上绘制一个三角形。
创建着色器模块
我们正在使用以下着色器代码。顶点着色器阶段(@vertex 块)接受一块包含位置和颜色的数据,根据给定位置定位顶点,插值颜色,然后将数据传递给片段着色器阶段。片段着色器阶段(@fragment 块)接受来自顶点着色器阶段的数据,并根据给定颜色为顶点着色。
const shaders = `
struct VertexOut {
@builtin(position) position : vec4f,
@location(0) color : vec4f
}
@vertex
fn vertex_main(@location(0) position: vec4f,
@location(1) color: vec4f) -> VertexOut
{
var output : VertexOut;
output.position = position;
output.color = color;
return output;
}
@fragment
fn fragment_main(fragData: VertexOut) -> @location(0) vec4f
{
return fragData.color;
}
`;
注意:在我们的演示中,我们将着色器代码存储在模板字面量中,但您可以将其存储在任何可以轻松作为文本检索并输入到 WebGPU 程序的地方。例如,另一个常见的做法是将着色器存储在 <script> 元素中,并使用 Node.textContent 检索内容。用于 WGSL 的正确 MIME 类型是 text/wgsl。
要使您的着色器代码可用于 WebGPU,您必须将其放入 GPUShaderModule 中,通过调用 GPUDevice.createShaderModule(),并将您的着色器代码作为描述符对象中的属性传递。例如
const shaderModule = device.createShaderModule({
code: shaders,
});
获取并配置画布上下文
在渲染管线中,我们需要指定一个渲染图形的地方。在这种情况下,我们正在获取对屏幕 <canvas> 元素的引用,然后调用 HTMLCanvasElement.getContext(),参数为 webgpu,以返回其 GPU 上下文(一个 GPUCanvasContext 实例)。
从那里,我们通过调用 GPUCanvasContext.configure() 配置上下文,向其传递一个选项对象,其中包含渲染信息将来自的 GPUDevice、纹理的格式,以及渲染半透明纹理时使用的 alpha 模式。
const canvas = document.querySelector("#gpuCanvas");
const context = canvas.getContext("webgpu");
context.configure({
device,
format: navigator.gpu.getPreferredCanvasFormat(),
alphaMode: "premultiplied",
});
注意:确定纹理格式的最佳实践是使用 GPU.getPreferredCanvasFormat() 方法;这会为用户的设备选择最有效的格式(bgra8unorm 或 rgba8unorm)。
创建缓冲区并将我们的三角形数据写入其中
接下来,我们将以 WebGPU 程序可以使用的形式提供数据。我们的数据最初以 Float32Array 提供,其中包含每个三角形顶点 8 个数据点——X、Y、Z、W 用于位置,R、G、B、A 用于颜色。
const vertices = new Float32Array([
0.0, 0.6, 0, 1, 1, 0, 0, 1, -0.5, -0.6, 0, 1, 0, 1, 0, 1, 0.5, -0.6, 0, 1, 0,
0, 1, 1,
]);
然而,这里有一个问题。我们需要将数据放入 GPUBuffer 中。在幕后,这种类型的缓冲区存储在与 GPU 核心紧密集成的内存中,以实现所需的高性能处理。附带效应是,主机系统(如浏览器)上运行的进程无法访问此内存。
通过调用 GPUDevice.createBuffer() 创建 GPUBuffer。我们给它一个等于 vertices 数组长度的大小,以便它可以包含所有数据,以及 VERTEX 和 COPY_DST 用途标志,以指示缓冲区将用作顶点缓冲区和复制操作的目标。
const vertexBuffer = device.createBuffer({
size: vertices.byteLength, // make it big enough to store vertices in
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
我们可以使用映射操作将数据写入 GPUBuffer,就像我们在计算管线示例中用于将数据从 GPU 读取回 JavaScript 一样。然而,在这种情况下,我们将使用方便的 GPUQueue.writeBuffer() 方法,该方法将其参数作为要写入的缓冲区、要从中写入的数据源、每个的偏移值以及要写入的数据大小(我们已指定数组的整个长度)。然后浏览器会找出处理数据写入的最有效方式。
device.queue.writeBuffer(vertexBuffer, 0, vertices, 0, vertices.length);
定义和创建渲染管线
现在我们已经将数据放入缓冲区,设置的下一步是实际创建我们的管线,准备好用于渲染。
首先,我们创建一个对象来描述我们的顶点数据所需的布局。这完美地描述了我们之前在 vertices 数组和顶点着色器阶段中看到的内容——每个顶点都有位置和颜色数据。两者都以 float32x4 格式格式化(映射到 WGSL vec4<f32> 类型),并且颜色数据从每个顶点中偏移 16 字节处开始。arrayStride 指定步幅,即构成每个顶点的字节数,stepMode 指定数据应按顶点获取。
const vertexBuffers = [
{
attributes: [
{
shaderLocation: 0, // position
offset: 0,
format: "float32x4",
},
{
shaderLocation: 1, // color
offset: 16,
format: "float32x4",
},
],
arrayStride: 32,
stepMode: "vertex",
},
];
接下来,我们创建一个描述符对象,该对象指定渲染管线阶段的配置。对于两个着色器阶段,我们指定可以在其中找到相关代码的 GPUShaderModule(shaderModule),以及作为每个阶段入口点的函数名称。
此外,在顶点着色器阶段,我们提供 vertexBuffers 对象来提供顶点数据的预期状态。在片段着色器阶段,我们提供一个颜色目标状态数组,指示指定的渲染格式(这与我们之前画布上下文配置中指定的格式匹配)。
我们还指定了一个 primitive 对象,在这种情况下,它只是说明我们将要绘制的基本体的类型,以及一个 auto 的 layout。layout 属性定义了在管线执行期间使用的所有 GPU 资源(缓冲区、纹理等)的布局(结构、目的和类型)。在更复杂的应用程序中,这将采用 GPUPipelineLayout 对象的样式,使用 GPUDevice.createPipelineLayout() 创建(您可以在我们的基本计算管线中看到一个示例),这允许 GPU 提前找出最有效地运行管线的方式。然而,我们指定了 auto 值,这将导致管线根据着色器代码中定义的任何绑定生成一个隐式绑定组布局。
const pipelineDescriptor = {
vertex: {
module: shaderModule,
entryPoint: "vertex_main",
buffers: vertexBuffers,
},
fragment: {
module: shaderModule,
entryPoint: "fragment_main",
targets: [
{
format: navigator.gpu.getPreferredCanvasFormat(),
},
],
},
primitive: {
topology: "triangle-list",
},
layout: "auto",
};
最后,我们可以基于我们的 pipelineDescriptor 对象创建一个 GPURenderPipeline,通过将其作为参数传递给 GPUDevice.createRenderPipeline() 方法调用。
const renderPipeline = device.createRenderPipeline(pipelineDescriptor);
运行渲染通道
现在所有设置都已完成,我们可以实际运行渲染通道并在我们的 <canvas> 上绘制一些东西。要编码任何稍后要发给 GPU 的命令,您需要创建一个 GPUCommandEncoder 实例,这可以通过调用 GPUDevice.createCommandEncoder() 来完成。
const commandEncoder = device.createCommandEncoder();
接下来,我们通过调用 GPUCommandEncoder.beginRenderPass() 创建一个 GPURenderPassEncoder 实例来启动渲染通道。此方法将一个描述符对象作为参数,其中唯一强制的属性是一个 colorAttachments 数组。在这种情况下,我们指定
- 一个要渲染到的纹理视图;我们通过
context.getCurrentTexture().createView()从<canvas>创建一个新视图。 - 一旦加载并在任何绘图发生之前,该视图应“清除”为指定的颜色。这就是导致三角形后面出现蓝色背景的原因。
- 当前渲染通道的值应为此颜色附件存储。
const clearColor = { r: 0.0, g: 0.5, b: 1.0, a: 1.0 };
const renderPassDescriptor = {
colorAttachments: [
{
clearValue: clearColor,
loadOp: "clear",
storeOp: "store",
view: context.getCurrentTexture().createView(),
},
],
};
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
现在我们可以调用渲染通道编码器的方法来绘制我们的三角形
- 调用
GPURenderPassEncoder.setPipeline()并将我们的renderPipeline对象作为参数,以指定用于渲染通道的管线。 - 调用
GPURenderPassEncoder.setVertexBuffer()并将我们的vertexBuffer对象作为参数,作为传递给管线进行渲染的数据源。第一个参数是设置顶点缓冲区的槽位,它指向描述此缓冲区布局的vertexBuffers数组中元素的索引。 GPURenderPassEncoder.draw()启动绘图。我们的vertexBuffer中有三个顶点的数据,因此我们将顶点计数设置为3以绘制所有顶点。
passEncoder.setPipeline(renderPipeline);
passEncoder.setVertexBuffer(0, vertexBuffer);
passEncoder.draw(3);
为了完成命令序列的编码并将其发布到 GPU,还需要三个步骤。
- 我们调用
GPURenderPassEncoder.end()方法以表示渲染通道命令列表的结束。 - 我们调用
GPUCommandEncoder.finish()方法来完成已发出命令序列的记录,并将其封装到GPUCommandBuffer对象实例中。 - 我们将
GPUCommandBuffer提交到设备的命令队列(由GPUQueue实例表示),以便发送到 GPU。设备的队列可通过GPUDevice.queue属性获得,并且可以通过调用GPUQueue.submit()将GPUCommandBuffer实例数组添加到队列中。
这三个步骤可以通过以下两行代码实现
passEncoder.end();
device.queue.submit([commandEncoder.finish()]);
基本计算管线
在我们的基本计算演示中,我们让 GPU 计算一些值,将它们存储在输出缓冲区中,将数据复制到暂存缓冲区,然后映射该暂存缓冲区,以便可以将数据读取到 JavaScript 并记录到控制台。
该应用程序遵循与基本渲染演示类似的结构。我们以与之前相同的方式创建 GPUDevice 引用,并通过调用 GPUDevice.createShaderModule() 将着色器代码封装到 GPUShaderModule 中。这里的区别在于我们的着色器代码只有一个着色器阶段,一个 @compute 阶段
// Define global buffer size
const NUM_ELEMENTS = 1000;
const BUFFER_SIZE = NUM_ELEMENTS * 4; // Buffer size, in bytes
const shader = `
@group(0) @binding(0)
var<storage, read_write> output: array<f32>;
@compute @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3u,
@builtin(local_invocation_id)
local_id : vec3u,
) {
// Avoid accessing the buffer out of bounds
if (global_id.x >= ${NUM_ELEMENTS}) {
return;
}
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
}
`;
创建缓冲区来处理我们的数据
在此示例中,我们创建了两个 GPUBuffer 实例来处理我们的数据,一个 output 缓冲区用于高速写入 GPU 计算结果,以及一个 stagingBuffer,我们将 output 的内容复制到其中,该缓冲区可以映射以允许 JavaScript 访问这些值。
output被指定为存储缓冲区,它将是复制操作的源。stagingBuffer被指定为可以映射以供 JavaScript 读取的缓冲区,并且将是复制操作的目标。
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
});
创建绑定组布局
创建管线时,我们指定要用于管线的绑定组。这首先涉及创建一个 GPUBindGroupLayout(通过调用 GPUDevice.createBindGroupLayout()),该布局定义了将在此管线中使用的 GPU 资源(例如缓冲区)的结构和目的。此布局用作绑定组遵循的模板。在此示例中,我们授予管线对单个内存缓冲区的访问权限,该缓冲区绑定到绑定槽 0(这与着色器代码中的相关绑定号 @binding(0) 匹配),可在管线的计算阶段使用,并且缓冲区的目的定义为 storage。
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
},
},
],
});
接下来,我们通过调用 GPUDevice.createBindGroup() 创建一个 GPUBindGroup。我们向此方法调用传递一个描述符对象,该对象指定此绑定组所基于的绑定组布局,以及要绑定到布局中定义的槽位的变量的详细信息。在此示例中,我们声明绑定 0,并指定应将我们之前定义的 output 缓冲区绑定到它。
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: output,
},
},
],
});
注意:您可以通过调用 GPUComputePipeline.getBindGroupLayout() 方法来检索创建绑定组时要使用的隐式布局。渲染管线也有一个版本:请参见 GPURenderPipeline.getBindGroupLayout()。
创建计算管线
有了以上所有内容,我们现在可以通过调用 GPUDevice.createComputePipeline() 并传递一个管线描述符对象来创建一个计算管线。这与创建渲染管线的方式类似。我们描述计算着色器,指定代码所在的模块和入口点。我们还为管线指定一个 layout,在这种情况下,通过调用 GPUDevice.createPipelineLayout() 基于我们之前定义的 bindGroupLayout 创建一个布局。
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout],
}),
compute: {
module: shaderModule,
entryPoint: "main",
},
});
这里与渲染管线布局的一个区别是,我们没有指定原始类型,因为我们没有绘制任何东西。
运行计算通道
运行计算通道的结构与运行渲染通道相似,但有一些不同的命令。首先,使用 GPUCommandEncoder.beginComputePass() 创建通道编码器。
在发出命令时,我们像以前一样使用 GPUComputePassEncoder.setPipeline() 指定要使用的管线。然后,我们使用 GPUComputePassEncoder.setBindGroup() 指定我们要使用 bindGroup 来指定计算中使用的数据,并使用 GPUComputePassEncoder.dispatchWorkgroups() 指定用于运行计算的 GPU 工作组数量。
然后,我们使用 GPURenderPassEncoder.end() 信号表示渲染通道命令列表的结束。
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups(Math.ceil(NUM_ELEMENTS / 64));
passEncoder.end();
将结果读回 JavaScript
在将编码的命令提交到 GPU 执行之前,我们使用 GPUCommandEncoder.copyBufferToBuffer() 将 output 缓冲区的内容复制到 stagingBuffer 缓冲区。
// Copy output buffer to staging buffer
commandEncoder.copyBufferToBuffer(
output,
0, // Source offset
stagingBuffer,
0, // Destination offset
BUFFER_SIZE, // Length, in bytes
);
// End frame by passing array of command buffers to command queue for execution
device.queue.submit([commandEncoder.finish()]);
一旦输出数据在 stagingBuffer 中可用,我们使用 GPUBuffer.mapAsync() 方法将数据映射到中间内存,使用 GPUBuffer.getMappedRange() 获取映射范围的引用,将数据复制到 JavaScript,然后将其记录到控制台。我们还在使用完 stagingBuffer 后将其解除映射。
// map staging buffer to read results back to JS
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // Offset
BUFFER_SIZE, // Length, in bytes
);
const copyArrayBuffer = stagingBuffer.getMappedRange(0, BUFFER_SIZE);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
console.log(new Float32Array(data));
GPU 错误处理
WebGPU 调用在 GPU 进程中异步验证。如果发现错误,问题调用在 GPU 端被标记为无效。如果又进行了依赖于无效调用返回值的调用,则该对象也将被标记为无效,依此类推。因此,WebGPU 中的错误被称为“传染性”错误。
每个 GPUDevice 实例都维护自己的错误范围堆栈。此堆栈最初是空的,但您可以通过调用 GPUDevice.pushErrorScope() 来将错误范围推送到堆栈以捕获特定类型的错误。
捕获错误完成后,可以通过调用 GPUDevice.popErrorScope() 结束捕获。这会将范围从堆栈中弹出,并返回一个 Promise,该 Promise 解析为一个对象(GPUInternalError、GPUOutOfMemoryError 或 GPUValidationError)描述范围内捕获的第一个错误,如果未捕获到错误,则返回 null。
我们已尝试在适当的“验证”部分中提供有用的信息,以帮助您了解 WebGPU 代码中发生错误的原因,其中列出了避免错误的条件。例如,请参见 GPUDevice.createBindGroup() 验证部分。其中一些信息很复杂;我们决定不重复规范,而是只列出以下错误条件:
- 不明显,例如导致验证错误的描述符属性组合。没有必要告诉您确保使用正确的描述符对象结构。这既明显又模糊。
- 由开发者控制。某些错误条件纯粹基于内部实现,与 Web 开发者无关。
您可以在解释器中找到有关 WebGPU 错误处理的更多信息——请参见 对象有效性和销毁状态 和 错误。WebGPU 错误处理最佳实践提供了有用的实际示例和建议。
注意:WebGL 中处理错误的历史方式是提供 getError() 方法来返回错误信息。这存在问题,因为它同步返回错误,这不利于性能——每次调用都需要往返 GPU,并且需要完成所有先前发出的操作。它的状态模型也是扁平的,这意味着错误可能会在不相关的代码之间泄露。WebGPU 的创建者决心改进这一点。
接口
API 入口点
-
API 的入口点——返回当前上下文的
GPU对象。 GPU-
使用 WebGPU 的起点。它可用于返回
GPUAdapter。 GPUAdapter-
表示一个 GPU 适配器。您可以从中请求
GPUDevice、适配器信息、功能和限制。 GPUAdapterInfo-
包含有关适配器的识别信息。
配置 GPUDevice
GPUDevice-
表示一个逻辑 GPU 设备。这是访问大多数 WebGPU 功能的主要接口。
GPUSupportedFeatures-
一个 类似集合 的对象,描述了
GPUAdapter或GPUDevice支持的附加功能。 GPUSupportedLimits-
描述
GPUAdapter或GPUDevice支持的限制。
配置渲染 <canvas>
HTMLCanvasElement.getContext()—"webgpu"contextType-
调用
getContext()并传入"webgpu"contextType会返回一个GPUCanvasContext对象实例,然后可以使用GPUCanvasContext.configure()对其进行配置。 GPUCanvasContext-
表示
<canvas>元素的 WebGPU 渲染上下文。
表示管线资源
GPUBuffer-
表示一块内存,可用于存储在 GPU 操作中使用的原始数据。
GPUExternalTexture-
一个包装对象,包含
HTMLVideoElement快照,可用作 GPU 渲染操作中的纹理。 GPUSampler-
控制着色器如何转换和过滤纹理资源数据。
GPUShaderModule-
对内部着色器模块对象的引用,一个 WGSL 着色器代码的容器,可以提交给 GPU 进行管线执行。
GPUTexture-
用于存储一维、二维或三维数据数组(例如图像)的容器,用于 GPU 渲染操作。
GPUTextureView-
对特定
GPUTexture定义的纹理子资源子集的一个视图。
表示管线
GPUBindGroup-
基于
GPUBindGroupLayout,GPUBindGroup定义了一组要绑定在一起的资源以及这些资源在着色器阶段中的使用方式。 GPUBindGroupLayout-
定义了管线中将使用的相关 GPU 资源(如缓冲区)的结构和目的,并用作创建
GPUBindGroup的模板。 GPUComputePipeline-
控制计算着色器阶段,可在
GPUComputePassEncoder中使用。 GPUPipelineLayout-
定义了管线使用的
GPUBindGroupLayout。在命令编码期间与管线一起使用的GPUBindGroup必须具有兼容的GPUBindGroupLayout。 GPURenderPipeline-
控制顶点和片段着色器阶段,可在
GPURenderPassEncoder或GPURenderBundleEncoder中使用。
编码并将命令提交给 GPU
GPUCommandBuffer-
表示已记录的 GPU 命令列表,可提交到
GPUQueue执行。 GPUCommandEncoder-
表示命令编码器,用于编码要发送到 GPU 的命令。
GPUComputePassEncoder-
编码与控制计算着色器阶段相关的命令,由
GPUComputePipeline发出。是GPUCommandEncoder整体编码活动的一部分。 GPUQueue-
控制已编码命令在 GPU 上的执行。
GPURenderBundle-
预先录制命令束的容器(参见
GPURenderBundleEncoder)。 GPURenderBundleEncoder-
用于预录制命令束。这些命令束可以通过
executeBundles()方法在GPURenderPassEncoder中重复使用,次数不限。 GPURenderPassEncoder-
编码与控制顶点和片段着色器阶段相关的命令,由
GPURenderPipeline发出。是GPUCommandEncoder整体编码活动的一部分。
对渲染通道运行查询
GPUQuerySet-
用于记录通道查询的结果,例如遮挡或时间戳查询。
调试错误
GPUCompilationInfo-
一个
GPUCompilationMessage对象数组,由 GPU 着色器模块编译器生成,用于帮助诊断着色器代码问题。 GPUCompilationMessage-
表示由 GPU 着色器模块编译器生成的一条信息、警告或错误消息。
GPUDeviceLostInfo-
当
GPUDevice.lostPromise解析时返回,提供有关设备丢失原因的信息。 GPUError-
由
GPUDevice.popErrorScope和uncapturederror事件公开的错误的基础接口。 GPUInternalError-
由
GPUDevice.popErrorScope和GPUDeviceuncapturederror事件公开的错误类型之一。表示操作因系统或实现特定原因失败,即使所有验证要求都已满足。 GPUOutOfMemoryError-
由
GPUDevice.popErrorScope和GPUDeviceuncapturederror事件公开的错误类型之一。表示没有足够的可用内存来完成请求的操作。 GPUPipelineError-
描述管线故障。当
Promise由GPUDevice.createComputePipelineAsync()或GPUDevice.createRenderPipelineAsync()调用拒绝时接收到的值。 GPUUncapturedErrorEvent-
GPUDeviceuncapturederror事件的事件对象类型。 GPUValidationError-
由
GPUDevice.popErrorScope和GPUDeviceuncapturederror事件公开的错误类型之一。描述应用程序错误,表明操作未通过 WebGPU API 的验证约束。
安全要求
整个 API 仅在 安全上下文 中可用。
示例
规范
| 规范 |
|---|
| WebGPU # gpu-interface |
浏览器兼容性
加载中…