Express 教程第 3 部分:使用数据库(使用 Mongoose)
本文简要介绍了数据库以及如何在 Node/Express 应用程序中使用它们。然后继续展示如何使用 Mongoose 为 LocalLibrary 网站提供数据库访问。它解释了如何声明对象模式和模型、主要字段类型以及基本验证。它还简要展示了一些访问模型数据的主要方法。
| 先决条件 | Express 教程第 2 部分:创建网站框架 |
|---|---|
| 目标 | 能够使用 Mongoose 设计和创建自己的模型。 |
概述
图书馆工作人员将使用 Local Library 网站存储有关书籍和借阅者的信息,而图书馆成员将使用它来浏览和搜索书籍,了解是否有任何副本可用,然后预订或借阅它们。为了有效地存储和检索信息,我们将把它存储在数据库中。
Express 应用程序可以使用许多不同的数据库,并且有几种方法可以用于执行Create、Read、Update 和Delete (CRUD) 操作。本教程简要概述了一些可用的选项,然后详细介绍了所选的特定机制。
我可以用哪些数据库?
与数据库交互的最佳方法是什么?
有两种常见的方法可以与数据库交互
- 使用数据库的原生查询语言,例如 SQL。
- 使用对象关系映射器 (“ORM”)。ORM 将网站的数据表示为 JavaScript 对象,然后将其映射到底层数据库。一些 ORM 与特定数据库绑定,而另一些则提供数据库无关的后端。
通过使用 SQL 或数据库支持的任何查询语言,可以获得最佳的性能。ODM 通常较慢,因为它们使用翻译代码在对象和数据库格式之间进行映射,这可能不会使用最有效的数据库查询(如果 ODM 支持不同的数据库后端,并且必须在支持哪些数据库功能方面做出更大的折衷,则尤其如此)。
使用 ORM 的好处是程序员可以继续使用 JavaScript 对象而不是数据库语义进行思考——如果您需要处理不同的数据库(在同一或不同的网站上),这一点尤其重要。它们还提供了一个明显的位置来执行数据验证。
注意:使用 ODM/ORM 通常会导致开发和维护成本降低!除非您非常熟悉原生查询语言或性能至关重要,否则您应该认真考虑使用 ODM。
我应该使用哪个 ORM/ODM?
npm 包管理器网站上提供了许多 ODM/ORM 解决方案(查看 odm 和 orm 标签以获取子集!)。
在撰写本文时,一些流行的解决方案是
- Mongoose:Mongoose 是一个 MongoDB 对象建模工具,旨在在异步环境中工作。
- Waterline:从基于 Express 的 Sails Web 框架中提取的 ORM。它为访问许多不同的数据库提供了一个统一的 API,包括 Redis、MySQL、LDAP、MongoDB 和 Postgres。
- Bookshelf:具有基于 Promise 和传统的回调接口,提供事务支持、急切/嵌套急切关系加载、多态关联以及对一对一、一对多和多对多关系的支持。适用于 PostgreSQL、MySQL 和 SQLite3。
- Objection:使尽可能轻松地使用 SQL 和底层数据库引擎的全部功能(支持 SQLite3、Postgres 和 MySQL)。
- Sequelize 是一个基于 Promise 的 Node.js 和 io.js ORM。它支持 PostgreSQL、MySQL、MariaDB、SQLite 和 MSSQL 方言,并具有强大的事务支持、关系、读取复制等功能。
- Node ORM2 是 NodeJS 的对象关系管理器。它支持 MySQL、SQLite 和 Postgres,有助于使用面向对象的方法处理数据库。
- GraphQL:主要是一种用于 RESTful API 的查询语言,GraphQL 非常流行,并且具有可用于从数据库读取数据的特性。
作为一般规则,在选择解决方案时,您应该同时考虑提供的功能和“社区活动”(下载量、贡献、错误报告、文档质量等)。在撰写本文时,Mongoose 是迄今为止最流行的 ODM,如果您使用 MongoDB 作为数据库,它是一个合理的选择。
为 LocalLibrary 使用 Mongoose 和 MongoDB
对于Local Library 示例(以及本主题的其余部分),我们将使用 Mongoose ODM 来访问我们的图书馆数据。Mongoose 充当 MongoDB 的前端,MongoDB 是一个开源的 NoSQL 数据库,它使用面向文档的数据模型。MongoDB 数据库中“文档”的“集合”类似于关系数据库中“行”的“表”。
这种 ODM 和数据库组合在 Node 社区中非常流行,部分原因是文档存储和查询系统非常类似于 JSON,因此 JavaScript 开发人员很熟悉。
注意:您无需了解 MongoDB 即可使用 Mongoose,尽管 Mongoose 文档 的某些部分确实更容易使用和理解,如果您已经熟悉 MongoDB。
本教程的其余部分将展示如何为 LocalLibrary 网站 示例定义和访问 Mongoose 模式和模型。
设计 LocalLibrary 模型
在您开始编写模型代码之前,花几分钟时间考虑一下我们需要存储哪些数据以及不同对象之间的关系是值得的。
我们知道我们需要存储有关书籍的信息(标题、摘要、作者、流派、ISBN),并且我们可能有多个副本可用(具有全局唯一的 ID、可用性状态等)。我们可能需要存储有关作者的信息,而不仅仅是他们的姓名,并且可能有多个作者具有相同或相似的姓名。我们希望能够根据书名、作者、流派和类别对信息进行排序。
在设计模型时,为每个“对象”(一组相关信息)创建单独的模型是有意义的。在这种情况下,这些模型的一些明显候选者是书籍、书籍实例和作者。
您可能还想使用模型来表示选择列表选项(例如,像一个下拉列表中的选项),而不是将选项硬编码到网站本身中——当并非所有选项都预先知道或可能发生更改时,建议这样做。一个很好的例子是流派(例如,奇幻、科幻等)。
一旦我们确定了模型和字段,我们就需要考虑它们之间的关系。
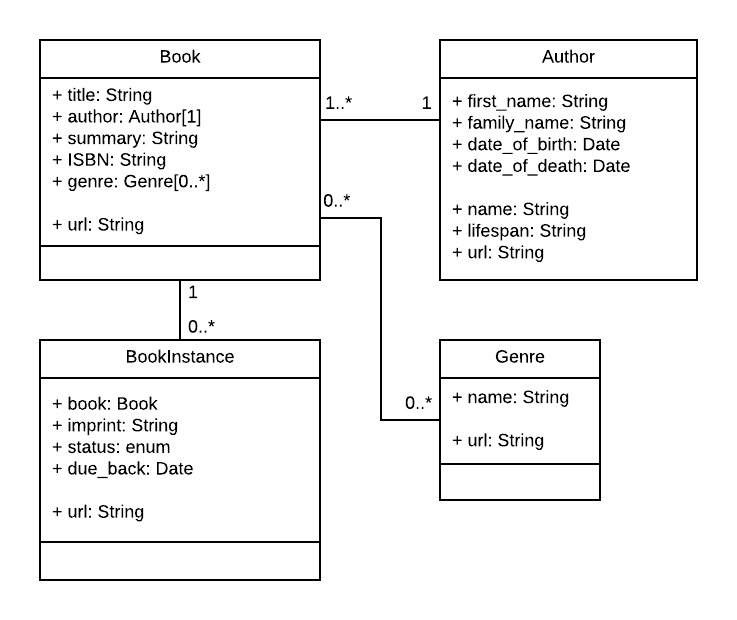
考虑到这一点,下面的 UML 关联图显示了我们将在此处定义的模型(作为框)。如上所述,我们为书籍(书籍的通用详细信息)、书籍实例(系统中可用书籍的特定物理副本的状态)和作者创建了模型。我们还决定为流派创建一个模型,以便可以动态创建值。我们决定不为BookInstance:status创建模型——我们将硬编码可接受的值,因为我们预计这些值不会改变。在每个框内,您可以看到模型名称、字段名称和类型,以及方法及其返回类型。
该图还显示了模型之间的关系,包括它们的多重性。多重性是图中显示的数字,表示关系中可能存在的每个模型的数量(最大值和最小值)。例如,框之间的连接线显示Book和Genre是相关的。Book模型附近的数字显示Genre必须具有零个或多个Book(任意多个),而线上另一端靠近Genre的数字显示一本Book可以具有零个或多个关联的Genre。
注意:如我们在下面的 Mongoose 入门 中所述,最好在一个模型中拥有定义文档/模型之间关系的字段(您仍然可以通过在另一个模型中搜索关联的_id来查找反向关系)。在下面,我们选择在 Book 模式中定义Book/Genre和Book/Author之间的关系,以及Book/BookInstance在BookInstance模式中的关系。这个选择在某种程度上是任意的——我们同样可以在另一个模式中拥有该字段。
注意:下一节提供了一个基本入门指南,解释了如何定义和使用模型。在阅读时,请考虑我们将如何构建上图中的每个模型。
数据库 API 是异步的
创建、查找、更新或删除记录的数据库方法是异步的。这意味着这些方法会立即返回,并且处理方法成功或失败的代码会在操作完成后稍后运行。在服务器等待数据库操作完成的同时,其他代码可以执行,因此服务器可以保持对其他请求的响应。
JavaScript 有许多机制来支持异步行为。历史上,JavaScript 很大程度上依赖于将 回调函数 传递给异步方法来处理成功和错误情况。在现代 JavaScript 中,回调已被 Promise 大量取代。Promise 是异步方法(立即)返回的对象,表示其未来的状态。当操作完成后,promise 对象会“完成”,并解析一个表示操作结果或错误的对象。
有两种主要方法可以使用 promise 在 promise 完成时运行代码,我们强烈建议您阅读 如何使用 promise 以获取这两种方法的高级概述。在本教程中,我们将主要使用 await 在 async function 中等待 promise 完成,因为这会导致更易读和易懂的异步代码。
这种方法的工作原理是,使用async function关键字将函数标记为异步函数,然后在该函数内部对返回 Promise 的任何方法应用await。当异步函数执行时,它的操作会在第一个await方法处暂停,直到 Promise 完成。从周围代码的角度来看,异步函数随后返回,并且其后的代码能够运行。稍后,当 Promise 完成时,异步函数内部的await方法会返回结果,或者如果 Promise 被拒绝则抛出错误。然后异步函数中的代码继续执行,直到遇到另一个await(此时它将再次暂停),或者直到函数中的所有代码都已运行。
您可以在下面的示例中看到它是如何工作的。myFunction()是一个异步函数,它在try...catch块内调用。当myFunction()运行时,代码执行在methodThatReturnsPromise()处暂停,直到 Promise 解析,此时代码继续执行到aFunctionThatReturnsPromise()并再次等待。如果异步函数中抛出错误,则catch块中的代码将运行,如果任一方法返回的 Promise 被拒绝,则会发生这种情况。
async function myFunction {
// ...
await someObject.methodThatReturnsPromise();
// ...
await aFunctionThatReturnsPromise();
// ...
}
try {
// ...
myFunction();
// ...
} catch (e) {
// error handling code
}
上面的异步方法按顺序执行。如果这些方法彼此不依赖,则可以并行运行它们,并更快地完成整个操作。这是使用Promise.all()方法完成的,该方法以 Promise 的可迭代对象作为输入并返回单个Promise。当所有输入的 Promise 都完成时,此返回的 Promise 就会完成,并包含一个包含完成值的数组。当任何输入的 Promise 被拒绝时,它就会被拒绝,并包含第一个拒绝原因。
下面的代码展示了它是如何工作的。首先,我们有两个返回 Promise 的函数。我们使用Promise.all()返回的 Promise 对它们都执行await以完成。一旦它们都完成,await就会返回并且结果数组被填充,然后函数继续到下一个await,并等待anotherFunctionThatReturnsPromise()返回的 Promise 完成。您可以在try...catch块中调用myFunction()以捕获任何错误。
async function myFunction {
// ...
const [resultFunction1, resultFunction2] = await Promise.all([
functionThatReturnsPromise1(),
functionThatReturnsPromise2()
]);
// ...
await anotherFunctionThatReturnsPromise(resultFunction1);
}
使用await/async的 Promise 允许对异步执行进行灵活且“易于理解”的控制!
Mongoose 入门
本节概述了如何将 Mongoose 连接到 MongoDB 数据库,如何定义模式和模型,以及如何执行基本查询。
注意:本入门指南深受npm上的Mongoose 快速入门和官方文档的影响。
安装 Mongoose 和 MongoDB
Mongoose 像任何其他依赖项一样安装在您的项目(package.json)中——使用 npm。要安装它,请在您的项目文件夹中使用以下命令
npm install mongoose
安装Mongoose会添加其所有依赖项,包括 MongoDB 数据库驱动程序,但它不会安装 MongoDB 本身。如果您想安装 MongoDB 服务器,则可以从此处下载各种操作系统的安装程序并在本地安装它。您也可以使用基于云的 MongoDB 实例。
注意:在本教程中,我们将使用基于云的MongoDB Atlas数据库即服务免费层来提供数据库。这适用于开发,并且对教程很有意义,因为它使“安装”与操作系统无关(数据库即服务也是您可能用于生产数据库的一种方法)。
连接到 MongoDB
Mongoose需要连接到 MongoDB 数据库。您可以像下面所示使用require()并使用mongoose.connect()连接到本地托管的数据库(对于本教程,我们将改为连接到互联网托管的数据库)。
// Import the mongoose module
const mongoose = require("mongoose");
// Set `strictQuery: false` to globally opt into filtering by properties that aren't in the schema
// Included because it removes preparatory warnings for Mongoose 7.
// See: https://mongoose.node.org.cn/docs/migrating_to_6.html#strictquery-is-removed-and-replaced-by-strict
mongoose.set("strictQuery", false);
// Define the database URL to connect to.
const mongoDB = "mongodb://127.0.0.1/my_database";
// Wait for database to connect, logging an error if there is a problem
main().catch((err) => console.log(err));
async function main() {
await mongoose.connect(mongoDB);
}
注意:如数据库 API 是异步的部分所述,这里我们在异步函数内对connect()方法返回的 Promise 执行await。我们使用 Promise 的catch()处理程序来处理连接尝试时发生的任何错误,但我们也可以在try...catch块中调用main()。
您可以使用mongoose.connection获取默认的Connection对象。如果您需要创建其他连接,可以使用mongoose.createConnection()。这采用与connect()相同的数据库 URI 格式(包含主机、数据库、端口、选项等),并返回一个Connection对象)。请注意,createConnection()会立即返回;如果您需要等待连接建立,则可以将其与asPromise()一起调用以返回一个 Promise(mongoose.createConnection(mongoDB).asPromise())。
定义和创建模型
模型使用Schema接口定义。模式允许您定义存储在每个文档中的字段以及它们的验证要求和默认值。此外,您可以定义静态和实例帮助器方法,以便更容易地处理您的数据类型,以及您可以像使用任何其他字段一样使用的虚拟属性,但这些属性实际上并未存储在数据库中(我们将在下面进一步讨论)。
然后,模式使用mongoose.model()方法“编译”成模型。拥有模型后,您可以使用它来查找、创建、更新和删除给定类型的对象。
注意:每个模型都映射到 MongoDB 数据库中的文档的集合。这些文档将包含在模型Schema中定义的字段/模式类型。
下面的代码片段显示了如何定义一个简单的模式。首先,您require() mongoose,然后使用 Schema 构造函数创建一个新的模式实例,在构造函数的对象参数中定义其中的各个字段。
定义模式
// Require Mongoose
const mongoose = require("mongoose");
// Define a schema
const Schema = mongoose.Schema;
const SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
在上面的例子中,我们只有两个字段,一个字符串和一个日期。在接下来的章节中,我们将展示一些其他的字段类型、验证和其他方法。
创建模型
模型使用mongoose.model()方法从模式创建。
// Define schema
const Schema = mongoose.Schema;
const SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
// Compile model from schema
const SomeModel = mongoose.model("SomeModel", SomeModelSchema);
第一个参数是将为您的模型创建的集合的单数名称(Mongoose 将为上面的模型SomeModel创建数据库集合),第二个参数是要用于创建模型的模式。
注意:定义完模型类后,您可以使用它们来创建、更新或删除记录,并运行查询以获取所有记录或特定记录子集。我们将在使用模型部分以及创建视图时向您展示如何执行此操作。
模式类型(字段)
一个模式可以有任意数量的字段——每个字段都代表存储在MongoDB中的文档中的一个字段。下面显示了一个示例模式,其中显示了许多常见的字段类型以及它们是如何声明的。
const schema = new Schema({
name: String,
binary: Buffer,
living: Boolean,
updated: { type: Date, default: Date.now() },
age: { type: Number, min: 18, max: 65, required: true },
mixed: Schema.Types.Mixed,
_someId: Schema.Types.ObjectId,
array: [],
ofString: [String], // You can also have an array of each of the other types too.
nested: { stuff: { type: String, lowercase: true, trim: true } },
});
大多数SchemaTypes(“type:”之后或字段名称之后的描述符)是不言自明的。例外情况是
ObjectId:表示数据库中模型的特定实例。例如,一本书可以使用它来表示其作者对象。这实际上将包含指定对象的唯一 ID(_id)。我们可以使用populate()方法在需要时提取关联的信息。Mixed:任意模式类型。[]:项目的数组。您可以对这些模型执行 JavaScript 数组操作(push、pop、unshift 等)。上面的示例显示了一个没有指定类型的对象数组和一个String对象的数组,但您可以拥有任何类型的对象数组。
代码还展示了两种声明字段的方式
- 字段名称和类型作为键值对(即像使用字段
name、binary和living一样)。 - 字段名称后跟一个对象,该对象定义了
type以及字段的任何其他选项。选项包括以下内容:- 默认值。
- 内置验证器(例如最大/最小值)和自定义验证函数。
- 字段是否必填
String字段是否应自动设置为小写、大写或修剪(例如{ type: String, lowercase: true, trim: true })
有关选项的更多信息,请参阅SchemaTypes(Mongoose 文档)。
验证
Mongoose 提供了内置和自定义验证器,以及同步和异步验证器。它允许您在所有情况下指定可接受的值范围和验证失败的错误消息。
内置验证器包括
下面的示例(略微修改自 Mongoose 文档)显示了如何指定一些验证器类型和错误消息
const breakfastSchema = new Schema({
eggs: {
type: Number,
min: [6, "Too few eggs"],
max: 12,
required: [true, "Why no eggs?"],
},
drink: {
type: String,
enum: ["Coffee", "Tea", "Water"],
},
});
有关字段验证的完整信息,请参阅验证(Mongoose 文档)。
虚拟属性
虚拟属性是您可以获取和设置但不会持久保存到 MongoDB 的文档属性。getter 用于格式化或组合字段,而 setter 用于将单个值分解成多个值以进行存储。文档中的示例从名和姓字段构造(并解构)一个完整的姓名虚拟属性,这比每次在模板中使用完整姓名时都构造它更简单、更干净。
注意:我们将在库中使用虚拟属性来使用路径和记录的_id值为每个模型记录定义唯一的 URL。
有关更多信息,请参阅虚拟属性(Mongoose 文档)。
方法和查询帮助器
模式还可以具有实例方法、静态方法和查询帮助器。实例方法和静态方法类似,但显而易见的区别在于实例方法与特定记录相关联,并且可以访问当前对象。查询帮助器允许您扩展 mongoose 的可链接查询构建器 API(例如,允许您除了find()、findOne()和findById()方法之外再添加一个“byName”查询)。
使用模型
创建模式后,您可以使用它来创建模型。模型表示数据库中您可以搜索的文档集合,而模型的实例表示您可以保存和检索的单个文档。
下面我们将简要概述。有关更多信息,请参阅:模型(Mongoose 文档)。
注意:记录的创建、更新、删除和查询都是异步操作,它们返回一个Promise。下面的示例仅显示了相关方法和await的使用(即使用这些方法的基本代码)。为了清晰起见,省略了周围的async function和try...catch块以捕获错误。有关使用await/async的更多信息,请参阅上面数据库 API 是异步的。
创建和修改文档
要创建记录,您可以定义模型的实例,然后在其上调用save()。下面的示例假设SomeModel是我们从模式创建的模型(具有单个字段name)。
// Create an instance of model SomeModel
const awesome_instance = new SomeModel({ name: "awesome" });
// Save the new model instance asynchronously
await awesome_instance.save();
您还可以使用create()在保存模型实例的同时定义它。下面我们只创建一个,但是您可以通过传入一个对象数组来创建多个实例。
await SomeModel.create({ name: "also_awesome" });
每个模型都有一个关联的连接(当您使用mongoose.model()时,这将是默认连接)。您可以创建一个新的连接并在其上调用.model()以在不同的数据库上创建文档。
您可以使用点语法访问此新记录中的字段,并更改值。您必须调用save()或update()才能将修改后的值存储回数据库。
// Access model field values using dot notation
console.log(awesome_instance.name); //should log 'also_awesome'
// Change record by modifying the fields, then calling save().
awesome_instance.name = "New cool name";
await awesome_instance.save();
搜索记录
您可以使用查询方法搜索记录,并将查询条件指定为 JSON 文档。下面的代码片段显示了如何查找数据库中所有打网球的运动员,仅返回运动员的姓名和年龄字段。这里我们只指定一个匹配字段(运动),但您可以添加更多条件,指定正则表达式条件,或完全删除条件以返回所有运动员。
const Athlete = mongoose.model("Athlete", yourSchema);
// find all athletes who play tennis, returning the 'name' and 'age' fields
const tennisPlayers = await Athlete.find(
{ sport: "Tennis" },
"name age",
).exec();
注意:务必记住,搜索未找到任何结果**不是错误**,但在应用程序的上下文中,它可能是一个失败情况。如果您的应用程序期望搜索找到一个值,您可以检查结果中返回的条目数量。
查询 API(例如find())返回类型为Query的变量。您可以使用查询对象分部分构建查询,然后使用exec()方法执行它。exec()执行查询并返回一个 Promise,您可以对其执行await以获取结果。
// find all athletes that play tennis
const query = Athlete.find({ sport: "Tennis" });
// selecting the 'name' and 'age' fields
query.select("name age");
// limit our results to 5 items
query.limit(5);
// sort by age
query.sort({ age: -1 });
// execute the query at a later time
query.exec();
上面我们在find()方法中定义了查询条件。我们也可以使用where()函数执行此操作,并且我们可以使用点运算符(.)将查询的所有部分链接在一起,而不是单独添加它们。下面的代码片段与我们上面的查询相同,但增加了年龄的额外条件。
Athlete.find()
.where("sport")
.equals("Tennis")
.where("age")
.gt(17)
.lt(50) // Additional where query
.limit(5)
.sort({ age: -1 })
.select("name age")
.exec();
find()方法获取所有匹配的记录,但通常您只需要获取一个匹配项。以下方法查询单个记录
findById():查找具有指定id的文档(每个文档都有一个唯一的id)。findOne():查找与指定条件匹配的单个文档。findByIdAndDelete()、findByIdAndUpdate()、findOneAndRemove()、findOneAndUpdate():通过id或条件查找单个文档,并更新或删除它。这些对于更新和删除记录很有用。
注意:还有一个countDocuments()方法,您可以使用它来获取与条件匹配的项目数。如果您想执行计数而不实际获取记录,这将很有用。
您可以使用查询执行更多操作。有关更多信息,请参阅:查询(Mongoose 文档)。
使用相关文档 - 填充
您可以使用ObjectId模式字段从一个文档/模型实例引用另一个文档/模型实例,或者使用ObjectId数组从一个文档引用多个文档。该字段存储相关模型的 ID。如果您需要关联文档的实际内容,则可以在查询中使用populate()方法将 ID 替换为实际数据。
例如,以下模式定义了作者和故事。每个作者可以有多个故事,我们将其表示为ObjectId数组。每个故事可以有一个作者。ref属性告诉模式可以为该字段分配哪个模型。
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const authorSchema = new Schema({
name: String,
stories: [{ type: Schema.Types.ObjectId, ref: "Story" }],
});
const storySchema = new Schema({
author: { type: Schema.Types.ObjectId, ref: "Author" },
title: String,
});
const Story = mongoose.model("Story", storySchema);
const Author = mongoose.model("Author", authorSchema);
我们可以通过分配_id值来保存对相关文档的引用。下面我们创建一个作者,然后创建一个故事,并将作者 ID 分配给故事的作者字段。
const bob = new Author({ name: "Bob Smith" });
await bob.save();
// Bob now exists, so lets create a story
const story = new Story({
title: "Bob goes sledding",
author: bob._id, // assign the _id from our author Bob. This ID is created by default!
});
await story.save();
注意:这种编程风格的一个好处是,我们不必用错误检查来使代码的主要路径复杂化。如果任何save()操作失败,Promise 将被拒绝并抛出错误。我们的错误处理代码单独处理(通常在catch()块中),因此代码的意图非常清楚。
我们的故事文档现在有一个由作者文档的 ID 引用的作者。为了在故事结果中获取作者信息,我们使用populate(),如下所示。
Story.findOne({ title: "Bob goes sledding" })
.populate("author") // Replace the author id with actual author information in results
.exec();
注意:敏锐的读者会注意到,我们向故事中添加了作者,但我们没有做任何事情来将故事添加到作者的stories数组中。那么我们如何获取特定作者的所有故事呢?一种方法是将我们的故事添加到 stories 数组中,但这会导致我们在两个地方需要维护有关作者和故事的信息。
更好的方法是获取作者的_id,然后使用find()在所有故事的作者字段中搜索它。
Story.find({ author: bob._id }).exec();
这几乎是您需要了解的关于本教程中处理相关项目的所有内容。有关更详细的信息,请参阅填充(Mongoose 文档)。
每个文件一个模式/模型
虽然您可以使用任何您喜欢的文件结构创建模式和模型,但我们强烈建议在每个模块(文件)中定义每个模型模式,然后导出创建模型的方法。如下所示
// File: ./models/somemodel.js
// Require Mongoose
const mongoose = require("mongoose");
// Define a schema
const Schema = mongoose.Schema;
const SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
// Export function to create "SomeModel" model class
module.exports = mongoose.model("SomeModel", SomeModelSchema);
然后,您可以在其他文件中立即需要并使用该模型。下面我们展示了如何使用它来获取模型的所有实例。
// Create a SomeModel model just by requiring the module
const SomeModel = require("../models/somemodel");
// Use the SomeModel object (model) to find all SomeModel records
const modelInstances = await SomeModel.find().exec();
设置 MongoDB 数据库
现在我们了解了 Mongoose 的一些功能以及我们希望如何设计模型,是时候开始LocalLibrary网站的工作了。我们首先要做的是设置一个 MongoDB 数据库,我们可以用它来存储我们的图书馆数据。
在本教程中,我们将使用MongoDB Atlas云托管沙盒数据库。此数据库层不适合生产网站,因为它没有冗余,但它非常适合开发和原型设计。我们在这里使用它是因为它是免费且易于设置的,并且因为 MongoDB Atlas 是一个流行的数据库即服务供应商,您可能会合理地将其选择为您的生产数据库(在撰写本文时,其他流行的选择包括ScaleGrid和ObjectRocket)。
注意:如果您愿意,可以通过下载并安装适合您系统的二进制文件在本地设置 MongoDB 数据库。本文档中的其余说明将类似,除了您在连接时指定的数据库 URL。在Express 教程第 7 部分:部署到生产环境教程中,我们在Railway上托管应用程序和数据库,但我们也可以同样使用MongoDB Atlas上的数据库。
您首先需要创建一个帐户与 MongoDB Atlas(这是免费的,只需要您输入基本的联系信息并确认其服务条款)。
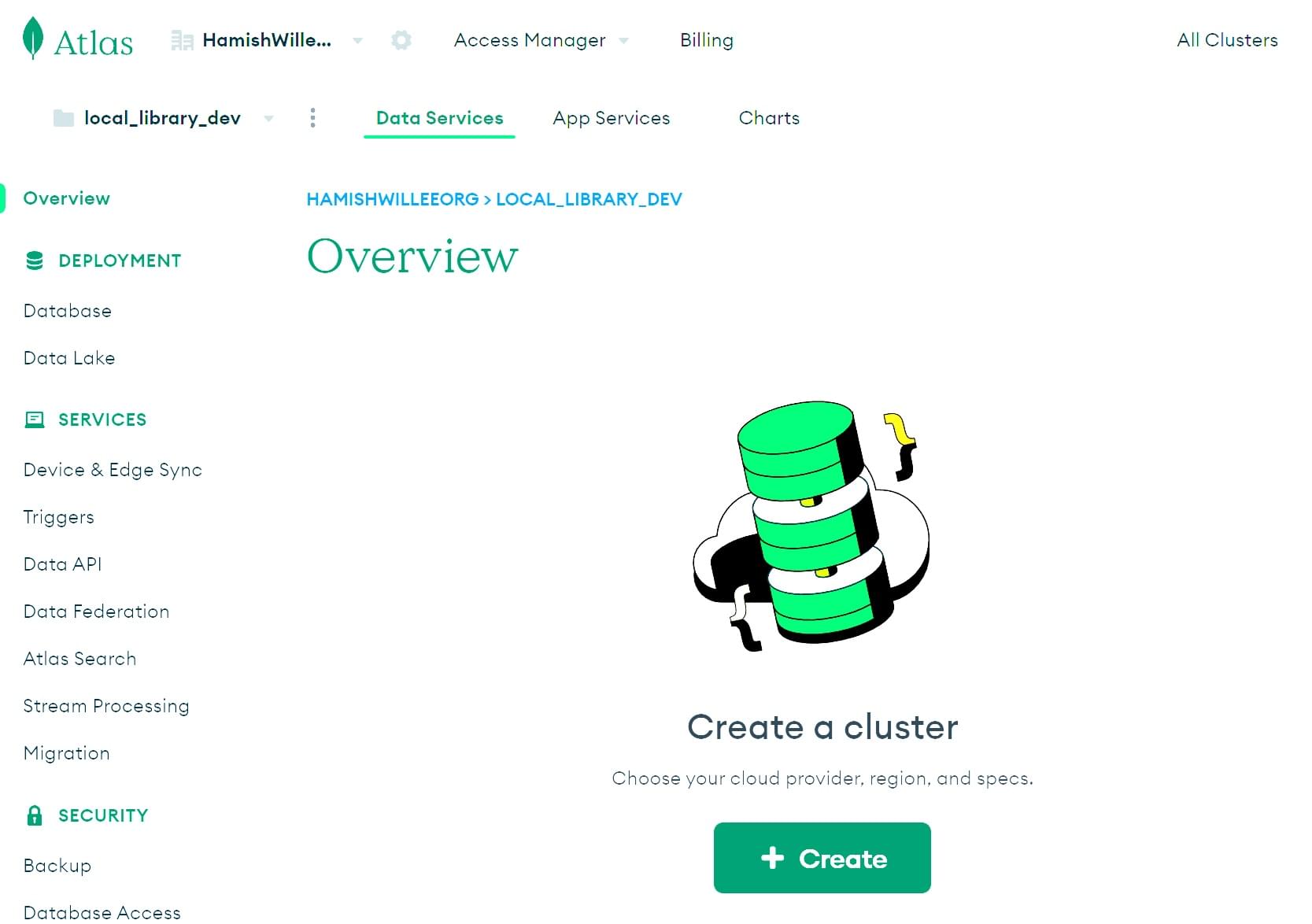
登录后,您将进入主页屏幕
- 点击概述部分中的+ 创建按钮。
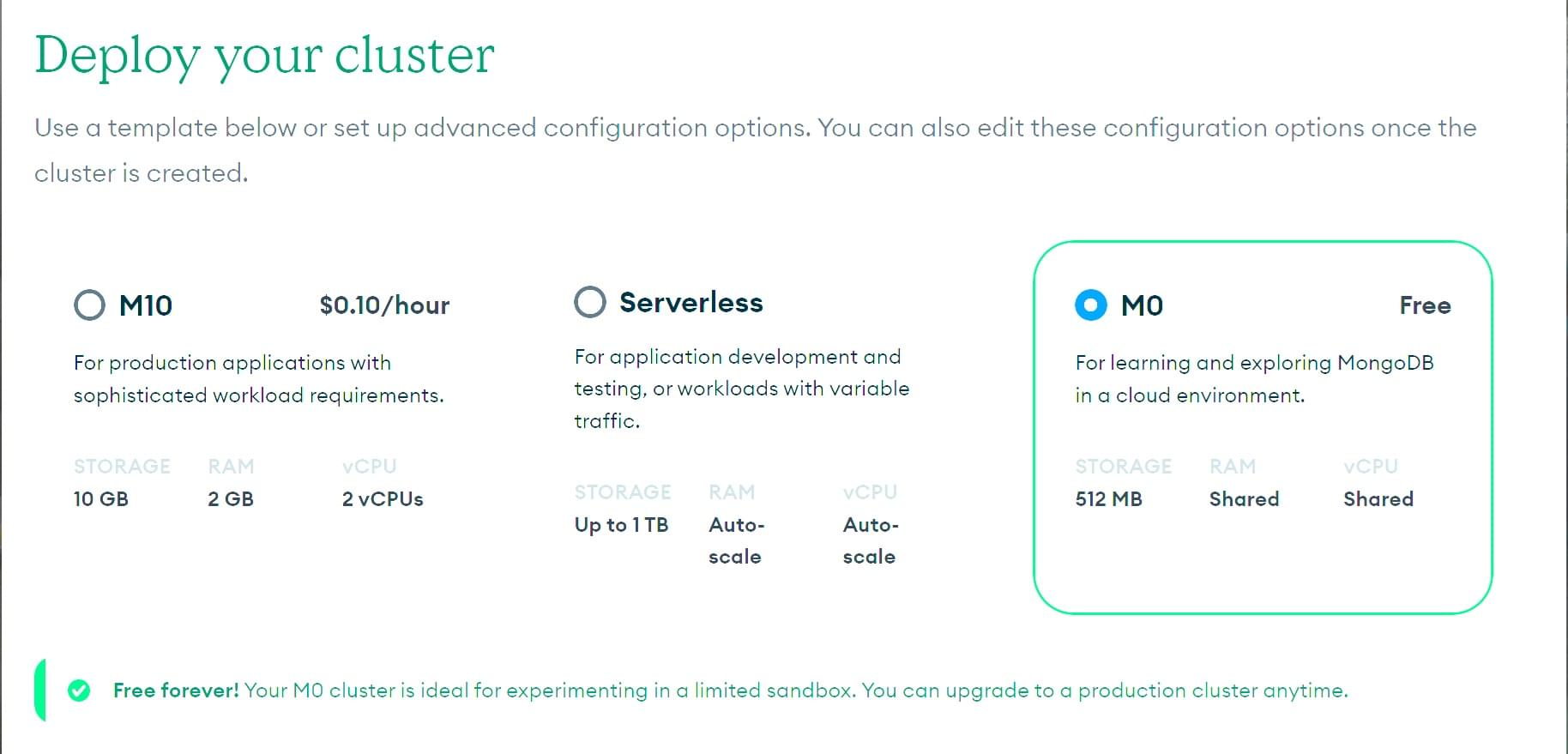
- 这将打开部署您的集群屏幕。点击M0 免费选项模板。
- 向下滚动页面以查看您可以选择的不同选项。
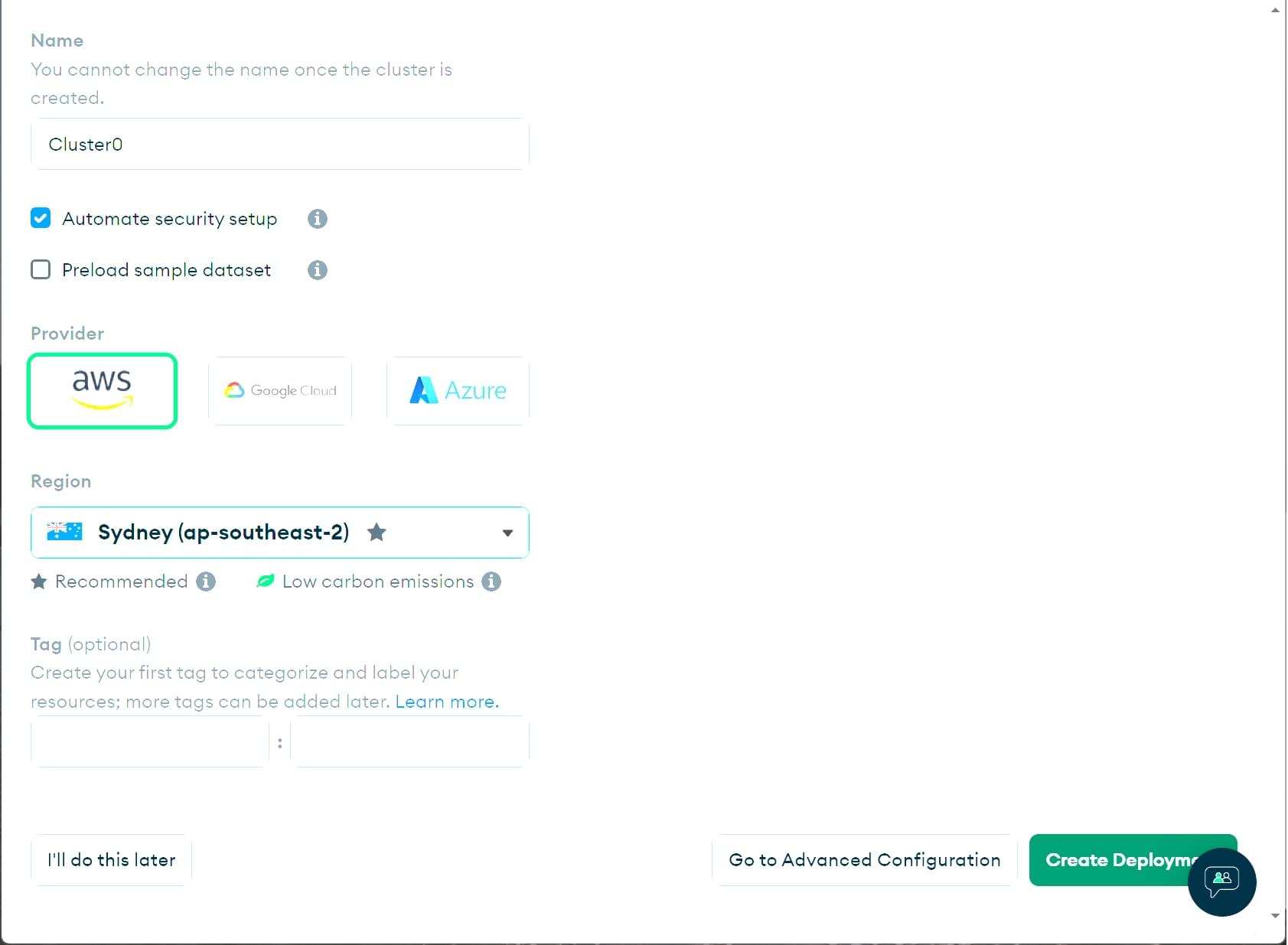
- 您可以在集群名称下更改集群的名称。在本教程中,我们将保留为
Cluster0。 - 取消选中预加载样本数据集复选框,因为我们稍后将导入我们自己的样本数据
- 从提供商和区域部分选择任何提供商和区域。不同的区域提供不同的提供商。
- 标签是可选的。我们在这里不会使用它们。
- 点击创建部署按钮(集群创建需要几分钟)。
- 您可以在集群名称下更改集群的名称。在本教程中,我们将保留为
- 这将打开安全快速入门部分。
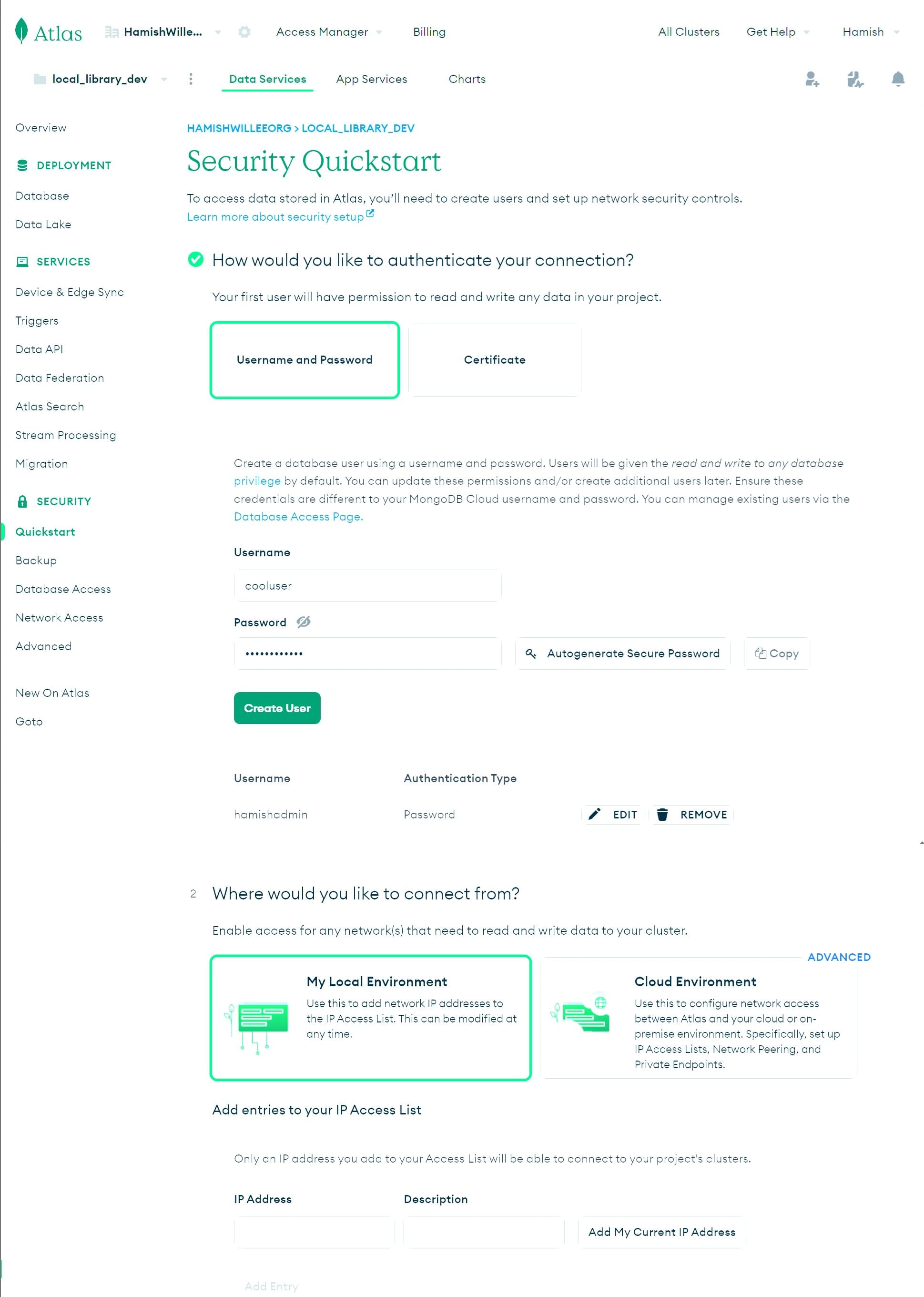
- 输入应用程序用于访问数据库的用户名和密码(上面我们创建了一个新的登录名“cooluser”)。请务必安全地复制和存储凭据,因为我们稍后将需要它们。点击创建用户按钮。
注意:避免在 MongoDB 用户密码中使用特殊字符,因为 mongoose 可能无法正确解析连接字符串。
- 选择按当前 IP 地址添加以允许从您的当前计算机访问
- 在 IP 地址字段中输入
0.0.0.0/0,然后点击添加条目按钮。这告诉 MongoDB 我们希望允许从任何地方访问。注意:最佳实践是限制可以连接到数据库和其他资源的 IP 地址。在这里,我们允许从任何地方连接,因为我们不知道部署后请求将来自哪里。
- 点击完成并关闭按钮。
- 输入应用程序用于访问数据库的用户名和密码(上面我们创建了一个新的登录名“cooluser”)。请务必安全地复制和存储凭据,因为我们稍后将需要它们。点击创建用户按钮。
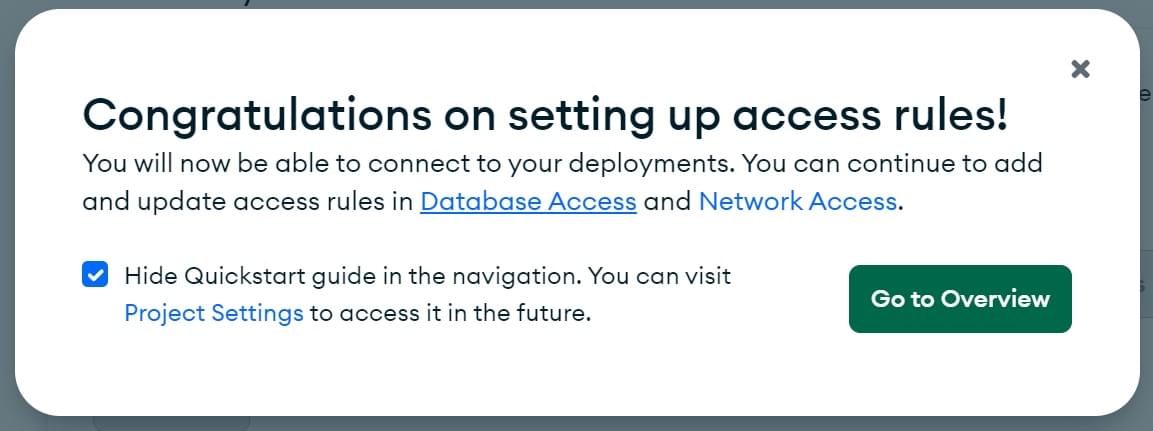
- 这将打开以下屏幕。点击转到概览按钮。
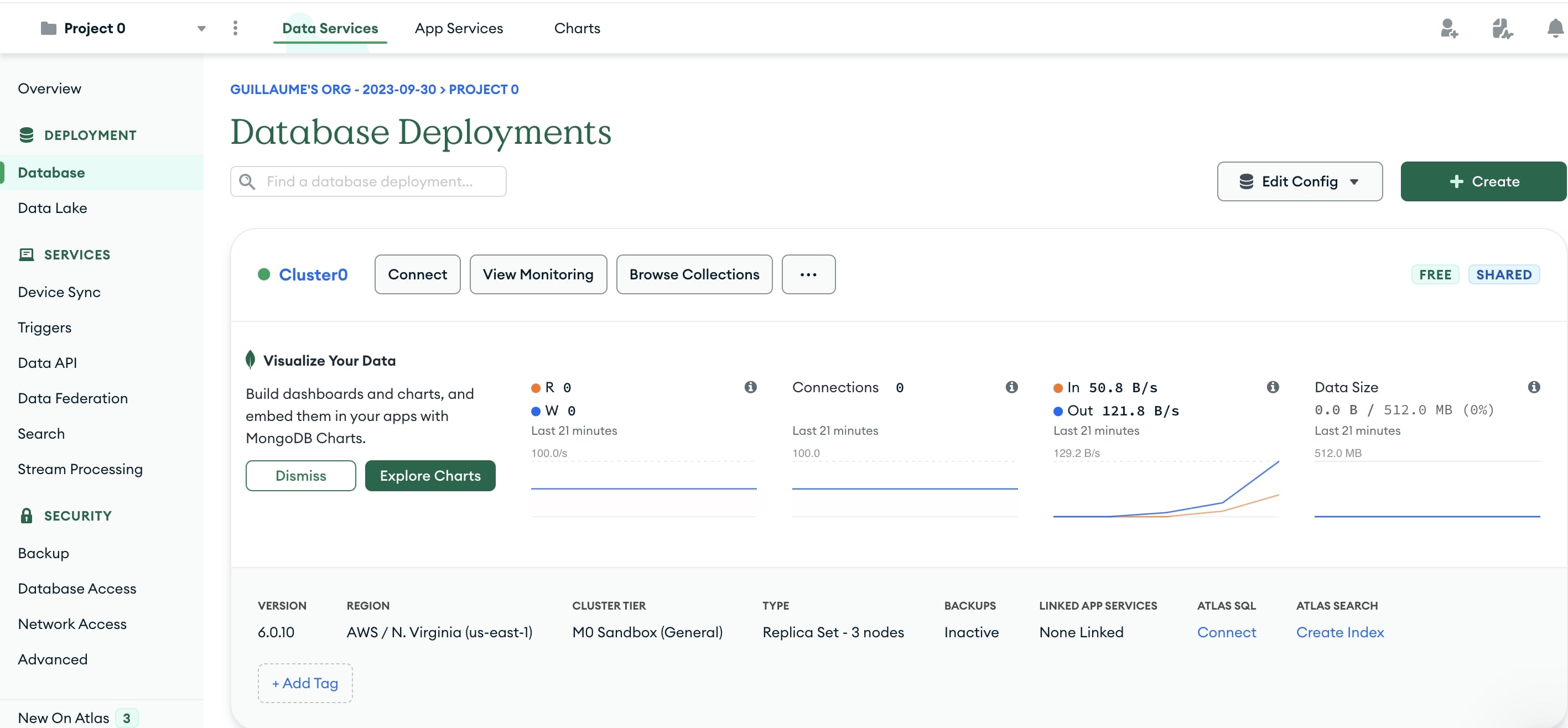
- 您将返回到概览屏幕。点击左侧部署菜单下的数据库部分。点击浏览集合按钮。
- 这将打开集合部分。点击添加我自己的数据按钮。
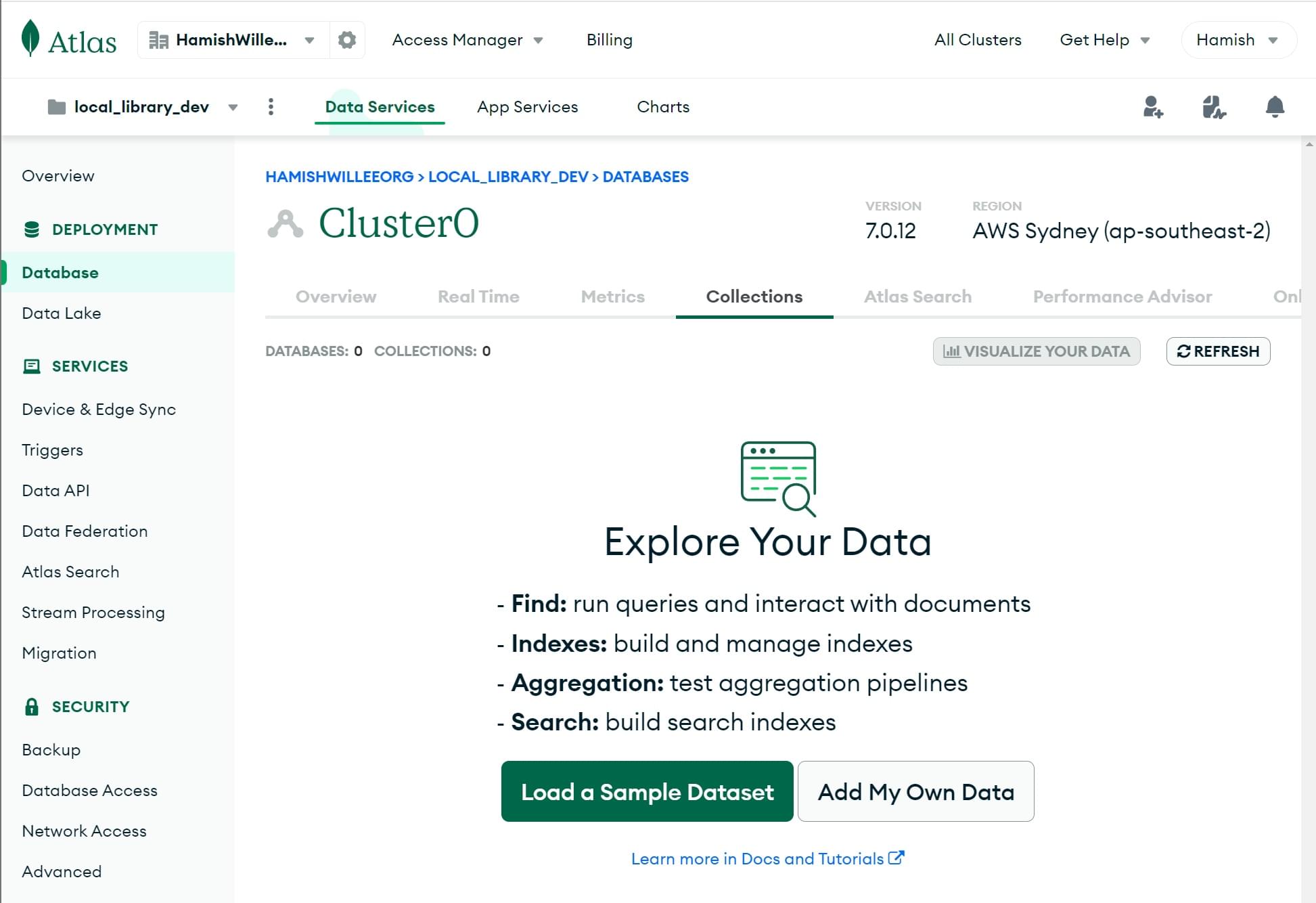
- 这将打开创建数据库屏幕。
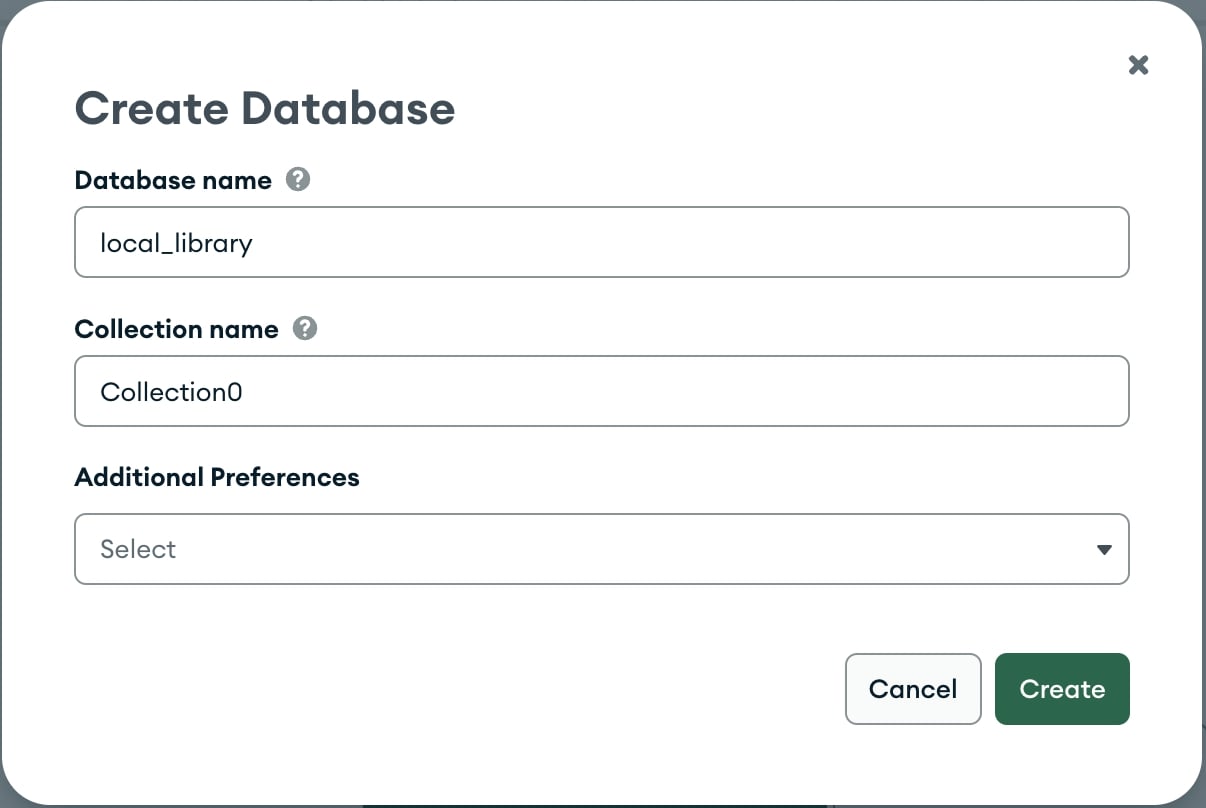
- 将新数据库的名称输入为
local_library。 - 将集合的名称输入为
Collection0。 - 点击创建按钮以创建数据库。
- 将新数据库的名称输入为
- 您将返回到集合屏幕,并且您的数据库已创建。
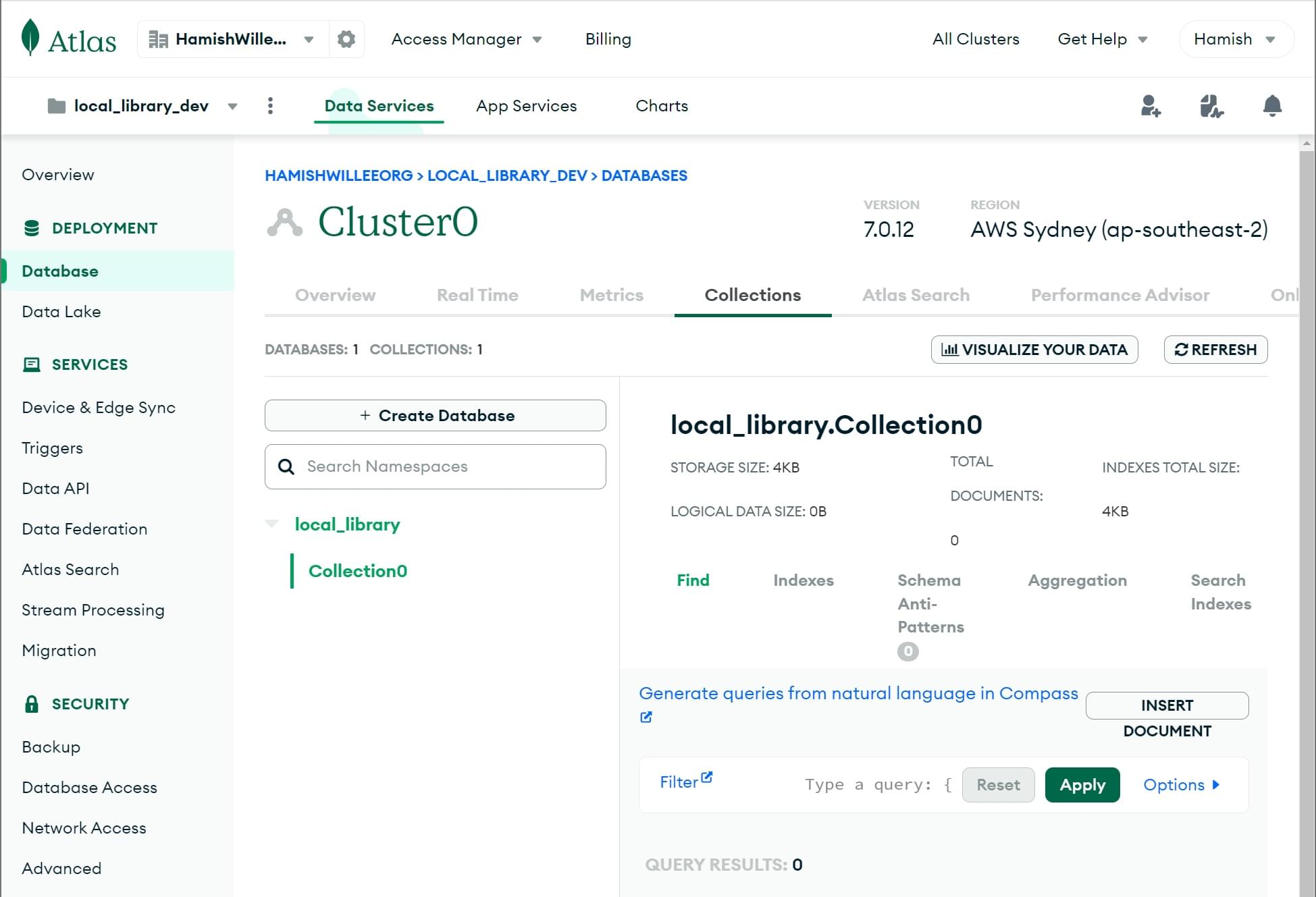
- 点击概览选项卡以返回到集群概览。
- 在 Cluster0 概览屏幕中,点击连接按钮。
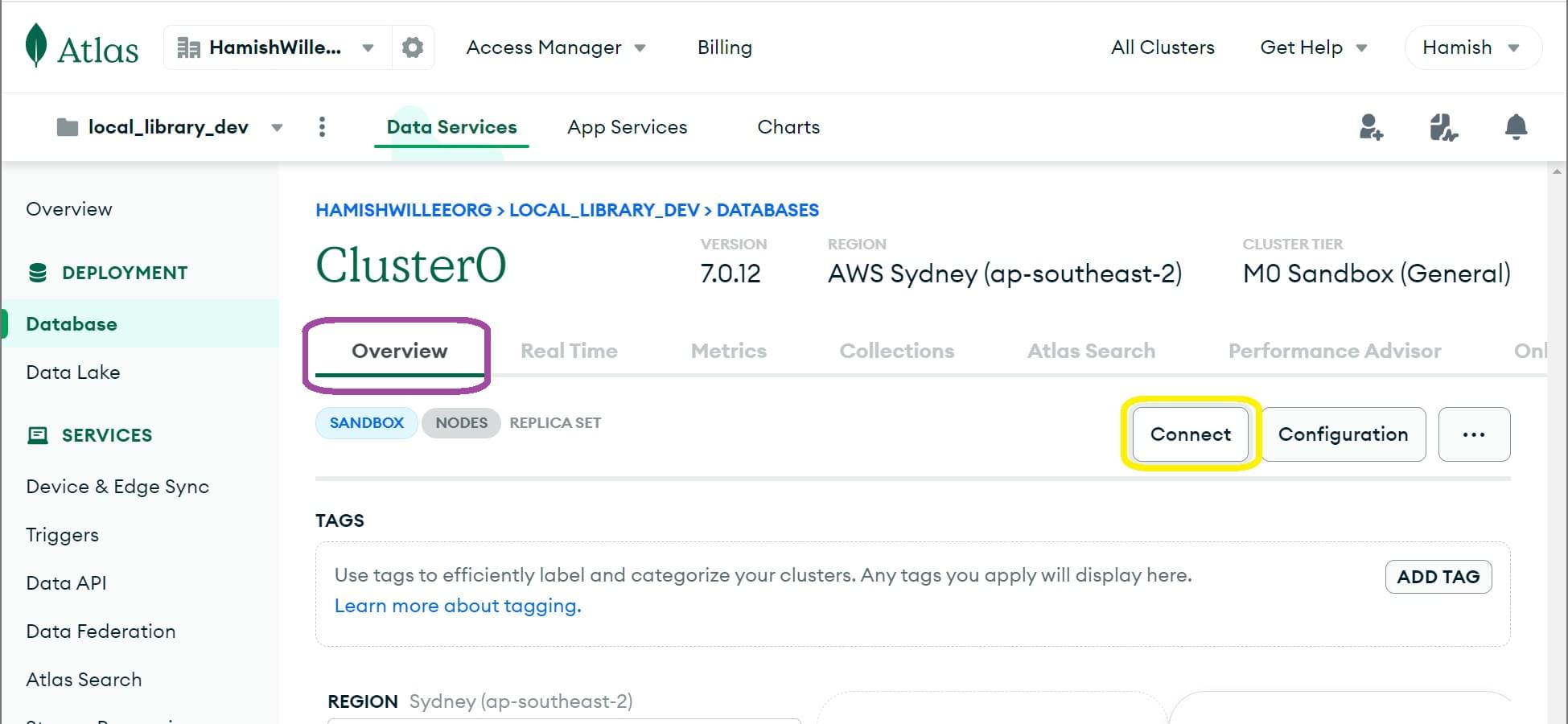
- 这将打开连接到 Cluster0屏幕。
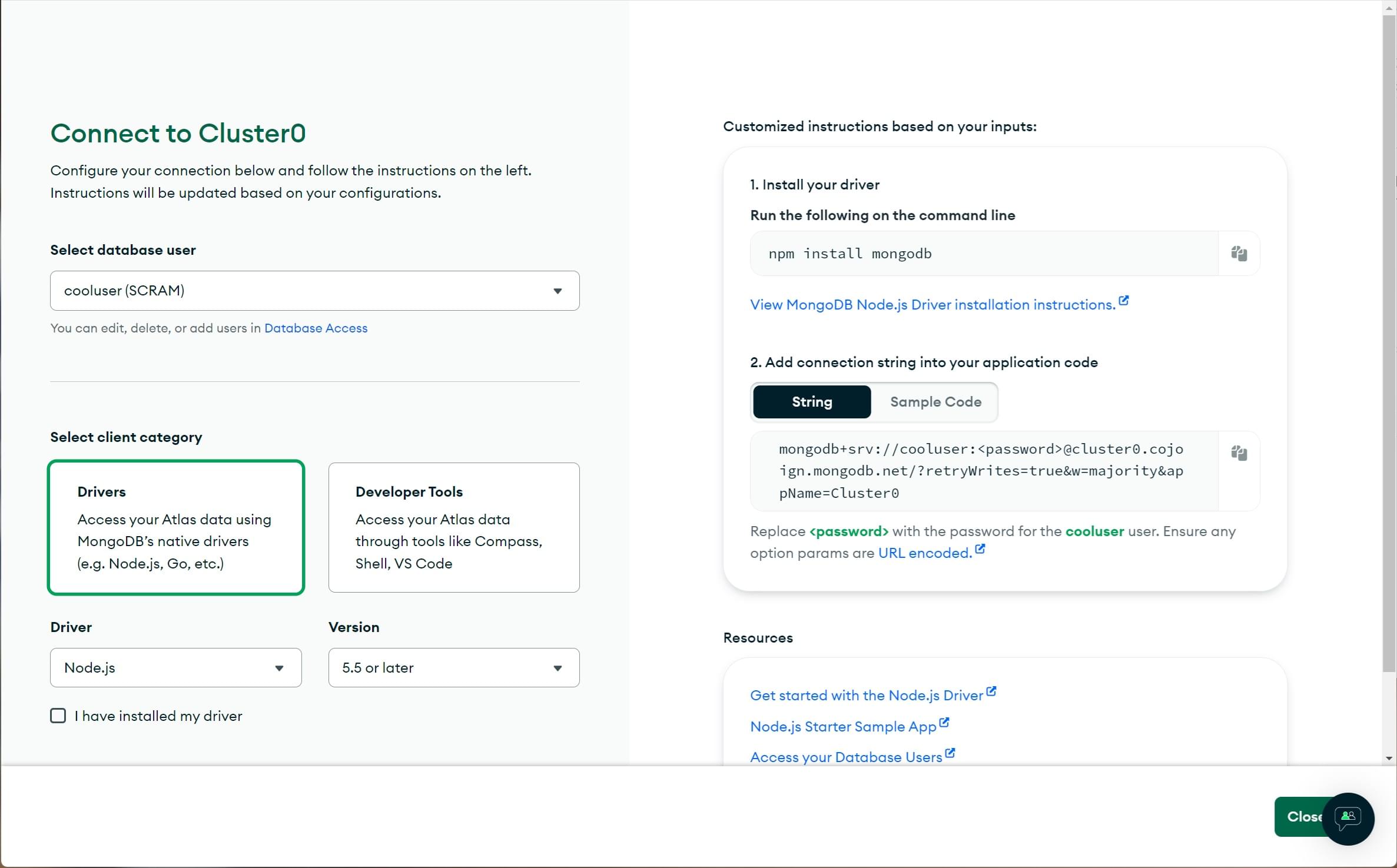
- 选择您的数据库用户。
- 选择驱动程序类别,然后选择驱动程序Node.js和版本,如所示。
- 不要按照建议安装驱动程序。
- 点击复制图标以复制连接字符串。
- 将其粘贴到您的本地文本编辑器中。
- 将连接字符串中的
<password>占位符替换为您的用户密码。 - 在选项之前的路径中插入数据库名称“local_library”(
...mongodb.net/local_library?retryWrites...) - 将包含此字符串的文件保存在安全的位置。
您现在已创建数据库,并且拥有一个可用于访问它的 URL(包含用户名和密码)。它看起来像这样:mongodb+srv://your_user_name:your_password@cluster0.cojoign.mongodb.net/local_library?retryWrites=true&w=majority&appName=Cluster0
安装 Mongoose
打开命令提示符并导航到创建本地图书馆网站框架的目录。输入以下命令以安装 Mongoose(及其依赖项)并将其添加到您的package.json文件中,除非您在阅读上面的Mongoose 入门指南时已执行此操作。
npm install mongoose
连接到 MongoDB
打开/app.js(在项目的根目录中)并在声明Express 应用程序对象的下方复制以下文本(在const app = express();行之后)。将数据库 URL 字符串('insert_your_database_url_here')替换为您自己的数据库的位置 URL(即使用MongoDB Atlas中的信息)。
// Set up mongoose connection
const mongoose = require("mongoose");
mongoose.set("strictQuery", false);
const mongoDB = "insert_your_database_url_here";
main().catch((err) => console.log(err));
async function main() {
await mongoose.connect(mongoDB);
}
如上面Mongoose 入门指南中所述,此代码创建到数据库的默认连接,并将任何错误报告到控制台。
请注意,如上所示在源代码中硬编码数据库凭据是不推荐的。我们在这里这样做是因为它显示了核心连接代码,并且因为在开发过程中,泄露这些详细信息不会造成暴露或破坏敏感信息的重大风险。我们将在部署到生产环境时向您展示如何更安全地执行此操作!
定义 LocalLibrary 架构
我们将为每个模型定义一个单独的模块,如上面所述。首先在项目根目录中创建模型文件夹(/models),然后为每个模型创建单独的文件
/express-locallibrary-tutorial // the project root
/models
author.js
book.js
bookinstance.js
genre.js
作者模型
复制下面显示的Author模式代码,并将其粘贴到您的./models/author.js文件中。该模式将作者定义为具有String SchemaTypes 的姓氏和名字(必填,最多 100 个字符),以及用于出生日期和死亡日期的Date字段。
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const AuthorSchema = new Schema({
first_name: { type: String, required: true, maxLength: 100 },
family_name: { type: String, required: true, maxLength: 100 },
date_of_birth: { type: Date },
date_of_death: { type: Date },
});
// Virtual for author's full name
AuthorSchema.virtual("name").get(function () {
// To avoid errors in cases where an author does not have either a family name or first name
// We want to make sure we handle the exception by returning an empty string for that case
let fullname = "";
if (this.first_name && this.family_name) {
fullname = `${this.family_name}, ${this.first_name}`;
}
return fullname;
});
// Virtual for author's URL
AuthorSchema.virtual("url").get(function () {
// We don't use an arrow function as we'll need the this object
return `/catalog/author/${this._id}`;
});
// Export model
module.exports = mongoose.model("Author", AuthorSchema);
我们还为 AuthorSchema 声明了一个名为“url”的虚拟属性,它返回获取模型特定实例所需的绝对 URL——每当我们需要获取特定作者的链接时,我们都会在模板中使用该属性。
注意:在模式中将我们的 URL 声明为虚拟属性是一个好主意,因为这样,项目的 URL 只需要在一个地方更改。此时,使用此 URL 的链接将无法工作,因为我们还没有任何处理单个模型实例的路由代码。我们将在后面的文章中设置这些内容!
在模块的末尾,我们导出模型。
书籍模型
复制下面显示的Book模式代码,并将其粘贴到您的./models/book.js文件中。大部分内容与作者模型类似——我们声明了一个具有多个字符串字段的模式,以及一个用于获取特定书籍记录的 URL 的虚拟属性,并且我们导出了模型。
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const BookSchema = new Schema({
title: { type: String, required: true },
author: { type: Schema.Types.ObjectId, ref: "Author", required: true },
summary: { type: String, required: true },
isbn: { type: String, required: true },
genre: [{ type: Schema.Types.ObjectId, ref: "Genre" }],
});
// Virtual for book's URL
BookSchema.virtual("url").get(function () {
// We don't use an arrow function as we'll need the this object
return `/catalog/book/${this._id}`;
});
// Export model
module.exports = mongoose.model("Book", BookSchema);
这里的主要区别在于我们创建了对其他模型的两个引用
- author 是对单个
Author模型对象的引用,并且是必需的。 - genre 是对
Genre模型对象数组的引用。我们还没有声明此对象!
BookInstance 模型
最后,复制下面显示的BookInstance模式代码,并将其粘贴到您的./models/bookinstance.js文件中。BookInstance表示某人可能借阅的书籍的特定副本,并包含有关副本是否可用、预计归还日期以及“印记”(或版本)详细信息的信息。
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const BookInstanceSchema = new Schema({
book: { type: Schema.Types.ObjectId, ref: "Book", required: true }, // reference to the associated book
imprint: { type: String, required: true },
status: {
type: String,
required: true,
enum: ["Available", "Maintenance", "Loaned", "Reserved"],
default: "Maintenance",
},
due_back: { type: Date, default: Date.now },
});
// Virtual for bookinstance's URL
BookInstanceSchema.virtual("url").get(function () {
// We don't use an arrow function as we'll need the this object
return `/catalog/bookinstance/${this._id}`;
});
// Export model
module.exports = mongoose.model("BookInstance", BookInstanceSchema);
我们在这里展示的新内容是字段选项
enum:这允许我们设置字符串的允许值。在这种情况下,我们使用它来指定书籍的可用状态(使用枚举意味着我们可以防止拼写错误和状态的任意值)。default:我们使用 default 将新创建的书籍实例的默认状态设置为“维护”,并将默认的due_back日期设置为now(注意如何在设置日期时调用 Date 函数!)。
其他所有内容都应该来自我们之前的模式。
流派模型 - 挑战
打开您的./models/genre.js文件,并创建一个用于存储流派(书籍的类别,例如它是小说还是非小说、浪漫还是军事历史等)的模式。
定义将与其他模型非常相似
- 该模型应该有一个名为
name的StringSchemaType 来描述流派。 - 此名称应该是必需的,并且必须在 3 到 100 个字符之间。
- 为流派的 URL 声明一个名为
url的虚拟属性。 - 导出模型。
测试 - 创建一些项目
就是这样。我们现在已经设置了网站的所有模型!
为了测试模型(并创建一些示例书籍和其他项目,以便我们可以在下一篇文章中使用),我们现在将运行一个独立脚本以创建每种类型的项目
- 在您的express-locallibrary-tutorial目录中下载(或以其他方式创建)文件populatedb.js(与
package.json处于同一级别)。注意:
populatedb.js中的代码可能对学习 JavaScript 有用,但了解它对于本教程不是必需的。 - 使用命令提示符中的 node 运行脚本,并传入您的MongoDB数据库的 URL(与您之前在
app.js中替换insert_your_database_url_here占位符的 URL 相同)bashnode populatedb <your MongoDB url>注意:在 Windows 上,您需要将数据库 URL 包含在双引号(")中。在其他操作系统上,您可能需要单引号(')。
- 脚本应该运行到完成,并在终端中显示其创建的项目。
注意:转到 MongoDB Atlas 上的数据库(在集合选项卡中)。您现在应该能够深入到书籍、作者、流派和书籍实例的各个集合中,并查看各个文档。
总结
在本文中,我们学习了有关 Node/Express 上的数据库和 ORM 的一些知识,以及有关如何定义 Mongoose 模式和模型的许多知识。然后,我们使用此信息为本地图书馆网站设计并实现了Book、BookInstance、Author和Genre模型。
最后,我们通过创建多个实例(使用独立脚本)来测试我们的模型。在下一篇文章中,我们将介绍如何创建一些页面来显示这些对象。
另请参阅
- 数据库集成(Express 文档)
- Mongoose 网站(Mongoose 文档)
- Mongoose 指南(Mongoose 文档)
- 验证(Mongoose 文档)
- 模式类型(Mongoose 文档)
- 模型(Mongoose 文档)
- 查询(Mongoose 文档)
- 填充(Mongoose 文档)