什么是空白?
空白字符在不同的编程语言环境中由不同的字符组成。就 CSS 空白处理规则而言,文档空白字符仅包括空格(U+0020)、制表符(U+0009)、换行符(LF, U+000A)和回车符(CR, U+000D),其中回车符在各方面都等同于空格。这些字符可以让你格式化代码以提高可读性。我们的源代码中充满了这些空白字符,我们通常只在生产构建步骤中为了减小文件大小而移除它们。
注意,此列表不包括不间断空格(U+00A0,在 HTML 中为 )。因此,这些字符不会触发任何折叠,这就是为什么它们经常被用来在 HTML 中创建更长的空格。
CSS 还定义了分段符的概念,在 HTML 的上下文中,它等同于 LF 字符。
HTML 如何处理空白?
有一种常见的误解是“HTML 会忽略空白”,这是不正确的:HTML 会保留你在源代码中写下的所有空白文本内容。作为一种标记语言,HTML 生成的 DOM 会保留文本内容中的所有空白,这些空白可以通过 Node.textContent 等 DOM API 进行检索和操作。如果 HTML 从 DOM 中剥离了空白,那么作为作用于 DOM 的下游渲染引擎,CSS 就无法使用 white-space 属性来保留它们。
备注: 需要明确的是,我们讨论的是HTML 标签之间的空白,这些空白在 DOM 中成为文本节点。任何标签内部的空白(在尖括号之间但不是属性值的一部分)只是 HTML 语法的一部分,不会出现在 DOM 中。
备注: 由于 HTML 解析的神奇之处(引自 DOM 规范),确实存在某些地方的空白字符可能被忽略的情况。例如,<html> 和 <head> 开始标签之间或 </body> 和 </html> 结束标签之间的空白会被忽略,不会出现在 DOM 中。此外,在解析 <pre> 元素的文本内容时,会剥离掉单个前导换行符。我们在此忽略这些边缘情况。
此外,HTML 解析器确实会对某些空白进行规范化:它会将 CR 和 CRLF 序列替换为单个 LF。但是,CR 字符也可以通过字符引用或 JavaScript 插入到 DOM 中,因此 CSS 空白处理规则仍然需要定义如何处理它们。
以下面的文档为例:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
其 DOM 树如下所示:

请注意:
- 一些文本节点将只包含空白。
- 其他文本节点可能在开头或结尾有空白。
备注: Firefox 开发者工具支持高亮显示文本节点,从而更容易地看出哪些节点包含空白字符。纯空白节点会标有“whitespace”标签。
在 DOM 中保留空白字符在很多方面都很有用,但也可能使某些布局更难实现,并可能给希望遍历 DOM 节点的开发者带来问题。我们将在稍后的解决空白节点的常见问题一节中探讨这些问题和一些解决方案。
CSS 如何处理空白?
当 DOM 传递给 CSS 进行渲染时,空白在默认情况下会被大量剥离。这意味着你的代码格式对最终用户是不可见的——在元素周围和内部创建空间是 CSS 的工作。
<!doctype html>
<h1> Hello World! </h1>
此源代码在 doctype 之后包含几个换行符,在 <h1> 元素之前、之后和内部有大量空格字符。但浏览器会忽略这些空格,只显示“Hello World!”,就好像这些字符根本不存在一样:
CSS 会忽略大部分(但不是全部)空白字符。在此示例中,“Hello”和“World!”之间的一个空格在页面渲染到浏览器中时仍然存在。CSS 使用特定的算法来决定哪些空白字符与用户无关,以及如何移除或转换它们。我们将在接下来的几节中解释这个处理过程。
折叠和转换
让我们看一个例子。为了让空白字符更清晰,我们还添加了一条注释,用 ◦ 表示所有空格,用 ⇥ 表示所有制表符,用 ⏎ 表示所有换行符:
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
此示例在浏览器中的渲染效果如下:
<h1> 元素包含:
- 一个文本节点(由一些空格、单词“Hello”、一个换行符和一些制表符组成)。
- 一个行内元素(
<span>,包含一个空格和单词“World!”)。 - 另一个文本节点(在
<span>之后有一个制表符和一些空格)。
因为这个 <h1> 元素只包含行内元素,所以它建立了一个行内格式化上下文。这是浏览器引擎用于在页面上排列内容的几种布局渲染上下文之一。
在这个行内格式化上下文中,空白字符的处理方式如下:
备注: 这个算法可以通过 white-space-collapse 属性(或其简写属性 white-space)进行配置。我们首先假设其默认值为(white-space-collapse: collapse),然后看看不同的属性值如何影响这个算法。
-
首先,紧接在换行符之前和之后的所有空格和制表符都会被忽略。所以,如果我们以前面的示例标记为例:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>……并应用这第一条规则,我们得到:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
接着,连续的换行符会被折叠成一个换行符。在这个例子中我们没有这种情况。
-
接下来,通过移除所有剩余的换行符,源代码中的行会被合并成单行。根据换行符前后的上下文,它们要么被转换成空格(U+0020),要么被直接移除。两者之间的具体选择取决于浏览器和语言。在我们这个英文例子中(单词之间用空格分隔),我们可以预期所有的换行符都会被“转换”成空格。所以我们最终得到:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1>值得注意的是,在没有词分隔符的语言中,比如中文,行与行之间合并时没有空格。所以:
html<div>你好 世界</div>可能会被渲染为“你好世界”,中间没有任何空格,这取决于浏览器的启发式算法。
-
接下来,所有制表符都会被转换成空格,所以例子变成:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>◦◦◦</h1> -
之后,紧跟在另一个空格之后的任何空格(即使跨越两个独立的行内元素)都会被忽略,所以我们最终得到:
html<h1>◦Hello◦<span>World!</span>◦</h1>
这就是为什么访问网页的人会看到“Hello World!”这个短语漂亮地写在页面顶部,而不是一个奇怪缩进的“Hello”后面跟着一个更奇怪缩进的“World!”在下一行。
在这些步骤之后,浏览器会处理换行和双向文本,我们在此忽略。注意,在 <h1> 开始标签之后和 </h1> 结束标签之前仍然有空格,但这些在浏览器中不会被渲染。我们接下来在布局每一行时处理这个问题。
不同的 white-space-collapse 值会跳过此算法的不同步骤:
preserve和break-spaces:整个算法被跳过,不发生任何空白折叠或转换。preserve-breaks:跳过步骤 2 和 3,保留换行符。preserve-spaces:整个算法被跳过,并替换为将每个制表符或换行符转换为一个空格的单一步骤。
简而言之,不同的空白字符会按以下方式被折叠和转换:
- 制表符通常被转换为空格。
- 如果要折叠分段符:
- 连续的分段符序列会折叠成单个分段符。
- 在使用空格分隔单词的语言(如英语)中,它们被转换为空格;而在不使用空格分隔单词的语言(如中文)中,它们被完全移除。
- 如果要折叠空格:
- 分段符之前或之后的空格或制表符被移除。
- 连续的空格序列会折叠成单个空格。
- 当保留空格时,连续的空格序列被视为不换行,但它们会在每个序列的末尾进行软换行——也就是说,下一行总是从下一个非空格字符开始。然而,对于
break-spaces值,软换行可能在每个空格之后发生,因此下一行可能以一个或多个空格开始。
修剪和定位
在行内和块级格式化上下文中,元素都以行为单位进行布局。在行内格式化上下文中,行是通过文本换行创建的。而在块级格式化上下文中,每个块级元素自己形成一行。在布局每一行时,空白会被进一步处理。让我们通过一个例子来解释这是如何工作的。
在这个例子中,和之前一样,我们用注释标记了空白字符。我们有三个只包含空白的文本节点:一个在第一个 <div> 之前,一个在两个 <div> 之间,还有一个在第二个 <div> 之后。
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>⇥Hello⇥</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
渲染效果如下:
这个例子中的空白处理如下:
备注: 这个算法可以通过 white-space-collapse 属性(或其简写属性 white-space)进行配置。我们首先假设其默认值为(white-space-collapse: collapse),然后看看不同的属性值如何影响这个算法。
-
首先,空白会像上一节看到的那样被折叠,将这个:
html<body>⏎ ⇥<div>⇥Hello⇥</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>……变成这个:
html<body>◦<div>◦Hello◦</div>◦<div>◦World!◦</div>◦</body>然后根据
<body>建立的块级格式化上下文来布局各行。在这个例子中,<body>的五个子节点每一个都被布局为单独的一行。(此代码块中的每一行代表渲染布局中的一行,而不是我们原始 HTML 代码中的一行)html<body> ◦ <div>◦Hello◦</div> ◦ <div>◦World!◦</div> ◦ </body>注意,如果行变得太长,每一行可能会换行并创建更多的行。实际上,浏览器是在布局行的同时确定行的内容的。我们将跳过文本换行工作原理的部分。
-
行首的连续空格被移除,所以例子变成:
html<body> <div>Hello◦</div> <div>World!◦</div> </body> -
此时保留的每个制表符都会根据
tab-size进行渲染。这只可能在white-space-collapse设置为preserve或break-spaces时发生,因为所有其他设置都会把制表符变成空格。 -
行尾的连续空格被移除,所以上面变成:
html<body> <div>Hello</div> <div>World!</div> </body>
我们现在有的三个空行在最终布局中不会占据任何空间,因为它们不包含任何可见内容。所以我们最终只会有两行在页面上占用空间。浏览网页的人会看到“Hello”和“World!”在两条独立的行上,正如你所期望的两个 <div> 的布局方式。浏览器基本上忽略了 HTML 代码中包含的所有空白。
不同的 white-space-collapse 值会跳过此算法的不同步骤:
preserve和break-spaces:除了步骤 3 外,整个算法都被跳过,所以不发生空白折叠或转换。preserve-spaces:整个算法都被跳过,所以行首和行尾的空白字符被保留。preserve-breaks:与collapse值应用相同的算法。
DOM API 如何处理空白?
如前所述,空白在 DOM 中是保留的。这意味着如果你获取 Node.textContent,你将得到与你在 HTML 源代码中编写的文本内容完全一致的内容;如果你获取 Node.childNodes,你将得到所有的文本节点,包括那些只包含空白的节点。
并非所有 DOM API 都会保留空白;有些 API 的设计就是为了处理渲染后的文本。例如,HTMLElement.innerText 返回的是与渲染结果完全一致的文本,所有空白都被折叠和修剪。 Selection.toString() 返回的是粘贴时的文本,这通常意味着空白被折叠。然而,在 Firefox 中(如前述折叠和转换一节所述,它会折叠中文字符间的空白),被折叠的空白在 toString() 返回的字符串和粘贴的文本中仍然被保留。
<div id="test">Hello world!</div>
const div = document.getElementById("test");
console.log(div.textContent); // " Hello\n world!\n"
console.log(div.innerText); // "Hello world!"
const selection = document.getSelection();
selection.selectAllChildren(div);
console.log(selection.toString()); // "Hello world!"
解决空白节点的常见问题
由于 CSS 的处理规则,空白节点对网站访问者是不可见的,但它们可能会干扰某些依赖于 DOM 确切结构的布局和 DOM 操作。让我们来看一些常见的问题以及如何解决它们。
行内元素和行内块元素之间的空白处理
让我们看一个关于空白节点的布局问题:行内元素和行内块元素之间的空格。正如我们之前看到的行内元素和块级元素一样,大多数空白字符被忽略,但像空格这样的单词分隔符仍然存在。最终进入布局的额外空白有助于分隔句子中的单词。
对于 inline-block 元素,情况变得更有趣:这些元素外部表现得像行内元素,内部则像块级元素。(它们常用于显示更复杂的 UI 组件,并排在同一行上,例如导航菜单项。)任何相邻的行内或行内块元素之间的空白都会在布局中产生空格,就像文本中单词之间的空格一样。(这可能会让开发者感到惊讶,因为它们是块级元素,而块级元素通常不会显示额外的空格。)
思考这个例子(和之前一样,我们在 HTML 代码中加入了注释来显示空白字符):
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #ff0066;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
渲染效果如下:
你可能不希望块之间有间隙。根据你的用例(例如头像列表或水平导航按钮行),你可能希望元素紧密相连,并能自己控制任何间距。
Firefox 开发者工具的 HTML 检查器可以高亮文本节点,并向你精确显示元素所占的区域。如果你怀疑有多余的外边距或意外的空白导致了间隙,这将非常有用。
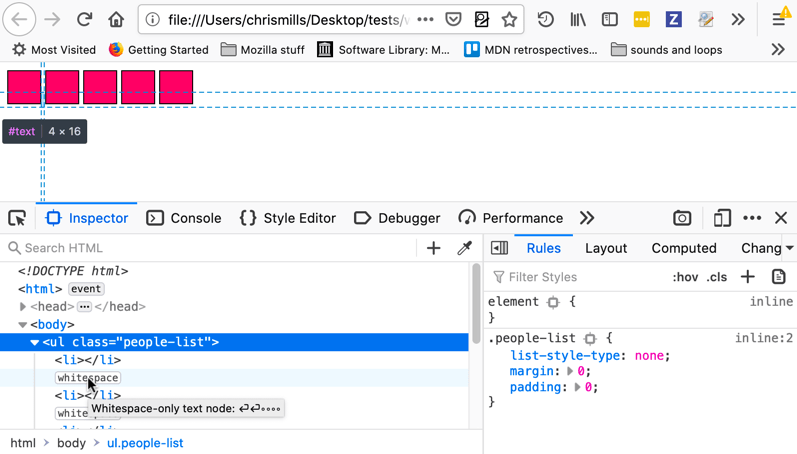
有几种方法可以解决这个问题:
-
使用 Flexbox 来创建水平项目列表,而不是尝试
inline-block解决方案。Flexbox 为你处理间距和对齐,绝对是首选方案:cssul { list-style-type: none; margin: 0; padding: 0; display: flex; } -
如果你需要依赖
inline-block,你可以将列表的font-size设置为0。这只在块的大小不是用em单位时才有效(因为em是基于font-size的,块的大小最终也会是0)。在这里使用rem单位会是一个不错的选择:cssul { font-size: 0; /* … */ } li { display: inline-block; width: 2rem; height: 2rem; /* … */ } -
或者,你可以在列表项上设置负外边距:
cssli { display: inline-block; width: 2rem; height: 2rem; margin-right: -0.25rem; } -
你也可以通过避免
<li>项之间出现空白节点来解决这个问题:html<li> ... </li><li> ... </li>
在 DOM 中处理空白
如前所述,空白在渲染时会被折叠和修剪,但在 DOM 中是保留的。这在尝试用 JavaScript 进行 DOM 操作时可能会带来一些陷阱。例如,如果你有一个父节点的引用,并想用 Node.firstChild 来操作它的第一个元素子节点,父节点开始标签后的一个意外的空白节点会给你错误的结果。该文本节点会被选中,而不是你想要的目标元素。
再举一个例子,如果你想对一部分元素根据它们是否为空(没有子节点)来做某些操作,你可以使用 Node.hasChildNodes()。但如果这些元素中任何一个包含了文本节点,你可能会得到错误的结果。
以下 JavaScript 代码展示了几个函数,可以更容易地处理 DOM 中的空白:
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use JavaScript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the `CharacterData` interface (i.e.,
* a `Text`, `Comment`, or `CDATASection` node)
* @return `true` if all of the text content of `nod` is whitespace,
* otherwise `false`.
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the `Node` interface.
* @return `true` if the node is:
* 1) A `Text` node that is all whitespace
* 2) A `Comment` node
* and otherwise `false`.
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // a comment node
(nod.nodeType === 3 && isAllWs(nod))
); // a text node, all ws
}
/**
* Version of `previousSibling` that skips nodes that are entirely
* whitespace or comments. (Normally `previousSibling` is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return The closest previous sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null` if
* no such node exists.
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `nextSibling` that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return The closest next sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null`
* if no such node exists.
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `lastChild` that skips nodes that are entirely
* whitespace or comments. (Normally `lastChild` is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return The last child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* Version of `firstChild` that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return The first child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* Version of `data` that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* `data` is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
以下代码演示了上述函数的使用。它遍历一个元素的所有子元素,找到文本内容为 "This is the third paragraph" 的那个,然后更改该段落的 class 属性和内容。
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = nodeAfter(cur);
}